

编者按:2021年,获得 ICCV 最佳论文奖的 Swin Transformer,通过在广泛的视觉问题上证明 Transformer 架构的有效性,加速了计算机视觉领域基本模型架构的变革。2021年末,微软亚洲研究院的研究员们又进一步提出了 Swin Transformer v2.0 版本,新版本训练了迄今为止最大的稠密视觉模型,并在多个主流视觉任务上大大刷新了记录,相关论文也已被 CVPR 2022 接收。研究员们希望借助 Swin Transformer v2.0 展现视觉大模型的“强悍”能力,呼吁整个领域加大对视觉大模型的投入,并为之提供相应的训练“配方”,从而为视觉领域的科研人员做进一步探索提供便利。那么,Swin Transformer v2.0 有哪些不同?今天就让我们来一探究竟吧!
人脑是大模型的一个典范。人的大脑拥有着千亿量级的神经元数目,和百万亿量级的连接数(参数)。而这样超大规模的模型为人脑成为目前唯一的通用智能“机器”提供了坚实的基础。在大容量下,人脑不仅在通常的智能任务中表现卓越,还具备极强的零样本和少样本迁移能力,从而可以快速适应新的环境和技能。
最近几年,自然语言处理(NLP)领域令人难以置信的成功就主要得益于对模型容量的大幅度扩展。短短几年时间,其模型容量扩大了几千倍,从3.4亿参数的 BERT 模型,进化到了拥有5300亿参数的 Megatron-Turing 模型,这些大型语言模型在语言理解和语言生成任务上都取得了长足的进步。同时,语言大模型还被证明具有极强的小样本甚至零样本学习能力。
与人脑和 NLP 的模型相比,计算机视觉领域的模型规模仍相对较小。视觉 Transformer 的出现为视觉模型的扩大提供了重要的基础,此前最大的稠密视觉模型是18亿参数的 ViT-G 模型和24亿参数的 CoAtNet 模型,它们都曾在 ImageNet-1K 图像分类任务上刷新了新的记录。但在更广泛的视觉任务中,大模型的效果仍然未知。
因此,探索如何进一步扩大视觉模型的规模,以及如何将其应用在更广泛的视觉任务上,是探索视觉大模型的重要问题。基于此目的,微软亚洲研究院的研究员们在 Swin Transformer 的基础上设计了 Swin Transformer v2.0,它具有30亿参数,是迄今为止最大的稠密视觉模型,可以有效地迁移到需要更高分辨率图像的各种视觉任务中。通过扩展模型容量和分辨率,Swin Transformer v2.0 已在四个具有代表性的基准上刷新了纪录,证明了视觉大模型在广泛视觉任务中的优势。
Swin Transformer打破视觉研究由CNN“统治”的局面
Swin Transformer 是一个通用的视觉 Transformer 骨干网络,它在物体检测和语义分割任务中大幅刷新了此前的纪录,并被广泛应用于众多视觉任务中,如图像生成、视频动作识别、视觉自监督学习、图像复原、医疗图像分割等。Swin Transformer 打破了计算机视觉领域被 CNN(卷积神经网络)长期“统治”的局面,加速了计算机视觉领域基本模型架构的变革,这一工作也因此获得了2021年 ICCV 最佳论文奖——马尔奖。
Swin Transformer 的核心思想在于将具有很强建模能力的 Transformer 结构与重要的视觉信号先验结合起来。这些先验包括层次性、局部性以及平移不变性等等。Swin Transformer 的一个重要设计是 shifted windows(移位的不重叠窗口),它可以大幅降低计算复杂度,让计算复杂度随着输入图像的大小呈线性增长;同时不同于传统的滑动窗,不重叠窗口的设计对硬件实现更加友好,从而具有更快的实际运行速度。

事实上,Swin Transformer 不是一个一蹴而就的工作,而是研究团队四年多在相关方向上不断坚持的结晶。“人脑成功的一个关键密码就是其拥有大量的新皮质,新皮质中的神经结构是统一和通用的,这就使得人类不用通过生物进化就可以实现和适应各种新的智能或者环境。在这方面,我们一直看好 Transformer 或者其中的注意力模块,三年前我们首次尝试将 Transformer 应用于视觉骨干网络的设计,并提出了局部关系网络 LR-Net,但当时的实用性还不足。Swin Transformer 通过引入移位窗口,终于达成了一个实用的视觉 Transformer 骨干网络,” 微软亚洲研究院视觉计算组高级研究员胡瀚说。
Swin Transformer 的目标是希望证明视觉 Transformer 能在广泛的视觉问题中超越此前占据主导地位的 CNN。如今该目标已达成,那么下一步做什么?胡瀚认为,“过去几年 NLP 领域最重要的发现之一就是扩大模型容量可以持续帮助各种 NLP 任务,并且模型越大,零样本和少样本学习的能力越强。所以我们希望探索计算机视觉中能否拥有同样的性质。”于是,Swin Transformer v2.0 诞生了。
在探索过程中,研究员们发现如下三个问题对于视觉大模型格外重要:
1. 如何解决大模型训练稳定性的问题
2. 如何将大模型应用于拥有更高分辨率的下游视觉任务的问题
3. 如何减少大模型对标注数据的要求
针对上述三个问题,Swin Transformer v2.0 给出了自己的回答。下面就让我们来详细了解一下。
30亿参数的Swin Transformer v2.0,稳定性与准确性双提升
在进一步扩大模型容量的过程中,微软亚洲研究院的研究员们发现训练过程存在严重的不稳定性问题。如图2所示,随着原始 Swin Transformer 模型从小变大,网络深层的激活值会急剧增加,拥有2亿参数的 Swin-L 模型,其幅值最高和最低层之间的差异可以达到10^4。当进一步将模型容量扩大到6.58亿参数,它会在训练过程中崩溃。

仔细观察原始 Swin Transformer 的架构,研究员们发现这是由于残差分支的输出直接加回主分支而导致的。原始的 Swin Transformer(以及绝大多数视觉 Transformer)在每个残差分支的开始都使用了预归一化(pre-normalization),它可以归一化输入的幅值,但对输出没有限制。在预归一化下,每个残差分支的输出激活值会直接合并回主分支,并被逐层累加,因而主分支的幅值会随着深度的增加而越来越大。这种不同层的幅值差异很大程度上导致了训练的不稳定性。
为了缓解这一问题,研究员们提出了一种新的归一化方式,称为残差后归一化(residual-post-normalization)。如图3所示,该方法将归一化层从每个残差分支的开始移到末尾,这样每个残差分支的输出在合并回主分支之前都会被归一化,当层数加深时,主分支的幅度将不会被累加。实验发现,这种新的归一化方式使得网络各层的激活值变得更加温和。
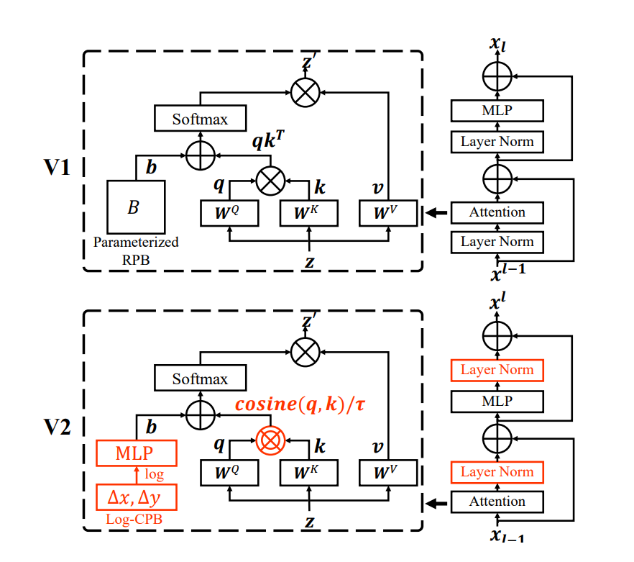
除此之外,研究员们还发现,随着模型变大,在原始的自注意力计算中,某些层的注意力权重往往会被几个特定的点所支配,特别是在使用后注意力的情况下。为了缓解这一问题,研究员们还提出了缩放的余弦注意力机制(scaled cosine attention),它可以取代之前的点乘注意力机制。在缩放的余弦注意力机制中,自注意力的计算与输入的幅值无关,从而可以产生更温和的注意力权重。
实验证明,以上两种技术不仅使大模型的训练过程更加稳定,而且还提高了准确性。
从低分辨率向高分辨率迁移,看Swin Transformer v2.0如何克服不良反应
视觉大模型的另一难题在于许多下游视觉任务需要高分辨率的输入图像或注意力窗口。由于预训练往往在低分辨率下进行,所以在高分辨率的下游任务上进行微调的窗口大小会产生显著变化。目前常见的做法是对位置偏置(position bias)进行双立方插值,这是一种随意的简单处理方式,其效果并不是最佳的。
为了解决这一问题,研究员们提出了对数空间的连续位置偏置(Log-spaced continuous position bias, Log-spaced CPB)。通过对对数空间的位置坐标应用一个小的元网络,Log-spaced CPB 可以产生任意坐标范围的位置偏置。由于元网络可以接受任意坐标,因此通过共享其权重,一个预训练好的模型可以在不同的窗口大小之间自由迁移。另一方面,通过将坐标转化到对数空间,在不同的窗口分辨率之间迁移所需的外推率要比使用原始线性空间坐标的外推率小得多,如图4所示。

借助 Log-spaced CPB,Swin Transformer v2.0 实现了模型在不同分辨率之间的平滑迁移。当把预训练分辨率从224像素缩小到192像素时,其结果也不会受到影响,并且计算速度还提升了50%,显著降低了训练类似体量的模型的成本。
模型容量和分辨率的扩大也导致了现有视觉模型的 GPU 显存消耗过高。为了解决显存问题,研究员们结合了几个重要的技术,包括零冗余优化器(zero-redundancy optimizer)、后向重计算(activation check-pointing)以及新提出的顺序自我注意计算力机制(sequential self-attention computation)。有了这些技术,大模型和大分辨率下的 GPU 显存消耗明显减少,而其对训练速度的影响却很小。
自监督学习SimMIM,解决视觉大模型的数据饥饿问题
训练越大的模型往往需要越多的数据,而相比 NLP,计算机视觉领域缺乏蕴含人类监督信息的数据来支撑大模型的训练。这就要求视觉领域在训练大模型时,要减少对标注数据的依赖,需要在更少量数据的情况下探索大模型。对此,研究员们通过引入自监督学习的掩码模型 SimMIM 来缓解这一问题。如图5所示,SimMIM 通过掩码图像建模(masked image modeling)来学习更好的图像表征。它采用随机掩码策略,用适度大的掩码块对输入图像做掩码;同时,通过直接回归来预测原始像素的 RGB 值;由于该模型的预测头很轻,所以只需要一层线性层即可。

SimMIM 非常简单且高效,借助 SimMIM,Swin Transformer v2.0 降低了对标注数据的需求,最终只用了7000万张带有噪声标签的图像就训练了30亿参数的模型。
有图有真相:v2.0性能“强悍”,在四大基准上均创新纪录
通过扩展模型容量和分辨率,Swin Transformer v2.0 在四个具有代表性的基准上均刷新了纪录,证明了视觉大模型在广泛视觉任务中的优势:在 ImageNet-V2 图像分类任务上 top-1 准确率为84.0%;在 COCO 物体检测任务上为63.1/54.4 box/mask mAP;在 ADE20K 语义分割上为59.9 mIoU;在 Kinetics-400 视频动作分类的 top-1 准确率为86.8%。


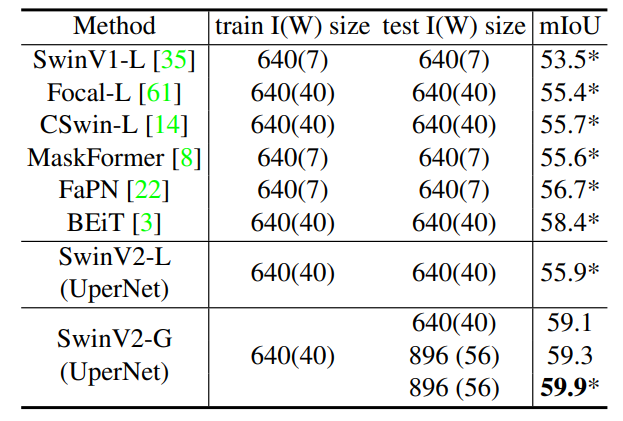
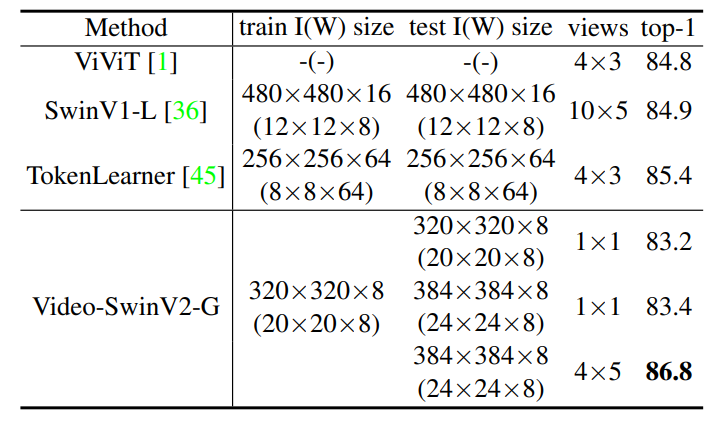
视觉大模型发展的三道坎:数据匮乏、学习方法和通用性
Swin Transformer v2.0 在众多视觉任务中的“强悍”性能证明了视觉大模型的潜力,同时,为视觉大模型提供了一个可行的训练“配方”。微软亚洲研究院的研究员们期望 Swin Transformer v2.0 可以为视觉领域的科研人员们做进一步前沿探索提供便利,并借此激励整个领域加大对视觉大模型的投入。
“我还是比较看好视觉大模型的”,胡瀚表示,“大模型已经证明通过增加模型容量可以持续提升性能的能力,其小样本甚至零样本能力也十分惊艳,而小样本能力对于实现通用智能非常关键”。
当然,胡瀚也认为视觉大模型仍旧面临一些挑战,“一是数据问题,视觉领域可用于训练的有效数据相比 NLP 领域还是有不小的差距。自监督是一个潜在的解决方法,但目前的自监督方法包括 SimMIM/BEiT/MAE/PeCo 等等都还不能利用好更大的数据,也就是证明更多的图像数据能帮助训练更好的模型。”
“二是,学习方法上还需要突破。现在在训练大模型方面,学界和业界对于自监督、图像分类和多模态方法均有所尝试,也取得了一些效果,但这些离我们真正解决问题还差的很远”。
“三是,如何建立视觉通用模型的问题还未知。现如今的视觉大模型大多还是依赖于预训练和微调的方式,不同的视觉应用仍需要依赖于不同的模型,如何能真正建立视觉的通用模型,用一个模型解决大部分问题,这还需要科研人员做大量的探索。”
视觉大模型的未来很光明,但也充满了挑战。微软亚洲研究院的研究员们期待更多同仁一起努力,推进视觉大模型的更多进展。
相关论文:
- Swin Transformer V2: Scaling Up Capacity and Resolution (opens in new tab)
- SimMIM: A Simple Framework for Masked Image Modeling (opens in new tab)
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (opens in new tab)
- Local Relation Networks for Image Recognition (opens in new tab)
相关 GitHub 链接: