

作者:机器学习组
编者按:研究与开发(R&D)是推动社会进步、经济增长和技术创新的核心动力。在人工智能时代,如何充分激发大语言模型的潜力,通过自动化手段提升研究与开发效率,实现跨领域知识迁移与创新,已成为 R&D 智能化转型的关键。为应对这一挑战,微软亚洲研究院推出了自动化研究与开发工具 RD-Agent,依托大语言模型的强大能力,开创了以人工智能驱动 R&D 流程自动化的新模式。RD-Agent 不仅提高了研发效率,还利用智能化的决策和反馈机制,为未来的跨领域创新与知识迁移提供了无限可能,赋能 R&D 迈向全新高度。

在现代工业中,研究与开发(R&D)是推动数字化转型和提升生产力与生产效率的关键。然而,随着人工智能技术的快速发展,传统 R&D 自动化方法的局限性逐渐显露。尤其是在提供高效、精准的自动化解决方案时,这些方法缺乏足够的智能,难以满足创新型研究和复杂开发任务的需求,远未能达到“像人类专家那样创造显著产业价值”的水平。相比之下,经验丰富的人类专家能够基于深厚的知识提出新想法、验证假设,并通过反复试验不断优化流程。
大语言模型(LLMs)的出现,为这些问题带来了全新的解决方案,并将为数据驱动的 R&D 场景的自动化产生巨大的推动作用。通过在各个领域的海量数据中进行训练,大语言模型积累了丰富的知识,能够提供传统方法所缺乏的智能性。凭借从数据中提取逻辑推理的能力,大语言模型可以支持复杂的决策过程,帮助自主执行任务,并在多种工作流程中作为智能代理(AI agent)发挥作用。
大语言模型为R&D注入新智能
微软亚洲研究院的研究员们认为,大语言模型在推动创新性研究方面具有巨大的潜力和价值,其广泛的知识覆盖面不仅有助于提出全新的想法和假设,还能够通过强大的推理能力为研究设计新的实验路径和方法,进而促进持续创新。在开发环节,大语言模型在数据处理和分析方面表现出色,能够高效提炼信息、总结规律。此外,凭借对代理工具(agentic tools)的灵活运用或创建能力,大语言模型可以自动处理重复且复杂的任务,从而显著加快开发进程。
为此,研究员们设计了一个基于大语言模型能力的自动化研究与开发工具 RD-Agent。通过整合数据驱动的 R&D 系统,RD-Agent 可以借助强大的人工智能能力驱动创新与开发的自动化。
RD-Agent 的核心是一个自主代理(autonomous agent)框架,由研究(R)和开发(D)两个关键模块构成。研究模块负责提出新想法,积极探索新的可能性;开发模块则专注于实现这些想法。两者相辅相成,在实际应用中通过反馈循环不断优化。随着时间推移,这些模块的能力将逐步提升,以应对日益复杂的研发需求。
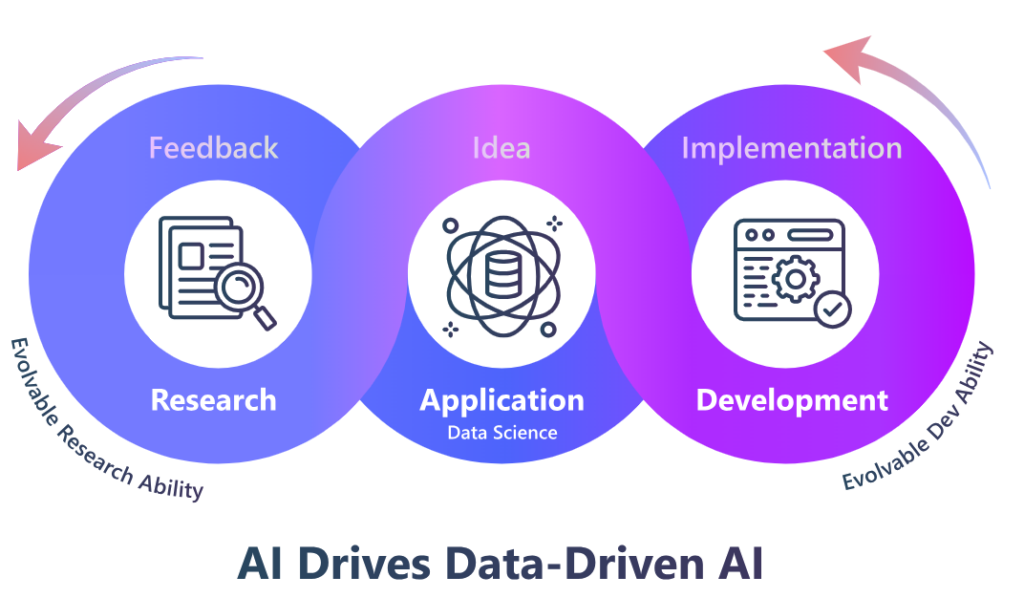
在实际应用中,RD-Agent 可以发挥众多作用,它既可以作为高效的研发助手,遵循指示完成日常繁琐的研发工作,也可以作为具有高度自主性的智能代理,主动提出创新性想法并自动进行探索研究。
以下是 RD-Agent 可支持的部分场景演示,包括了从通用研究助理到辅助特定专业领域的数据智能研发:
- 作为通用科研助理 (opens in new tab),自动阅读研究论文或报告,并实现模型结构。
- 自动探索和实现模型结构,挖掘数据规律:如金融 (opens in new tab)、医疗 (opens in new tab)等领域。
- 作为自动化 Quant 工厂 (opens in new tab),在复杂的真实系统中,自动化完成大量耗时的特征工程工作。
目前,RD-Agent 工具已在 GitHub 上开源,微软亚洲研究院的研究员们正不断更新和扩展 RD-Agent 的功能,以适应更多的方法和场景,进一步优化研发过程,提高生产率。
RD-Agent GitHub 链接:https://github.com/microsoft/rd-agent (opens in new tab)
RD-Agent的关键挑战与技术创新
在数据驱动的 R&D 自动化领域,大语言模型的应用带来了革命性的创新机遇。然而,实现这一愿景的关键挑战在于如何获取并持续进化专业知识。
具体来说,现有的大语言模型在完成初始训练后,其能力很难持续增长。因为大语言模型的训练过程更侧重于通用知识学习,所以对于高度专业化知识的理解并不透彻,而这些专业知识需要从行业内的深度实践中获得,这成为了解决领域内复杂研发问题的一大难题。
微软亚洲研究院的研究员们认识到,只有深入探索研发阶段,并持续获得深度领域知识,才可能让大语言模型的研发能力不断增长。因此,研究员们从研究、开发、测试基准三个层面展开了研究,进而设计了 RD-Agent 工具,实现了在真实世界的实践和反馈中的动态学习。
研究层面:探索新的想法并通过反馈对其优化。在 R&D 过程中,提出和验证新想法是研究的核心环节。数据挖掘专家会首先提出假设,例如循环神经网络 RNN 能够捕捉时间序列数据中的模式;然后设计实验,如在包含时间序列的金融数据场景中验证该假设;随后将实验想法转化为代码,例如 PyTorch 模型结构;最后执行代码以获取反馈,诸如指标、损失曲线等。专家们会从反馈中学习,并在下一次迭代中改进。
受这些理念的启发,研究员们建立了一个基本的方法框架,支持自动提出和验证假设,并从实践反馈中积累知识。RD-Agent 是首个将科学研究自动化和实践验证相连接的框架,并融入了知识管理机制,使其在探索中能够像人类专家一样不断地验证和积累知识。随着 agent 对场景的理解逐步加深,它还能提出更优的解决方案。
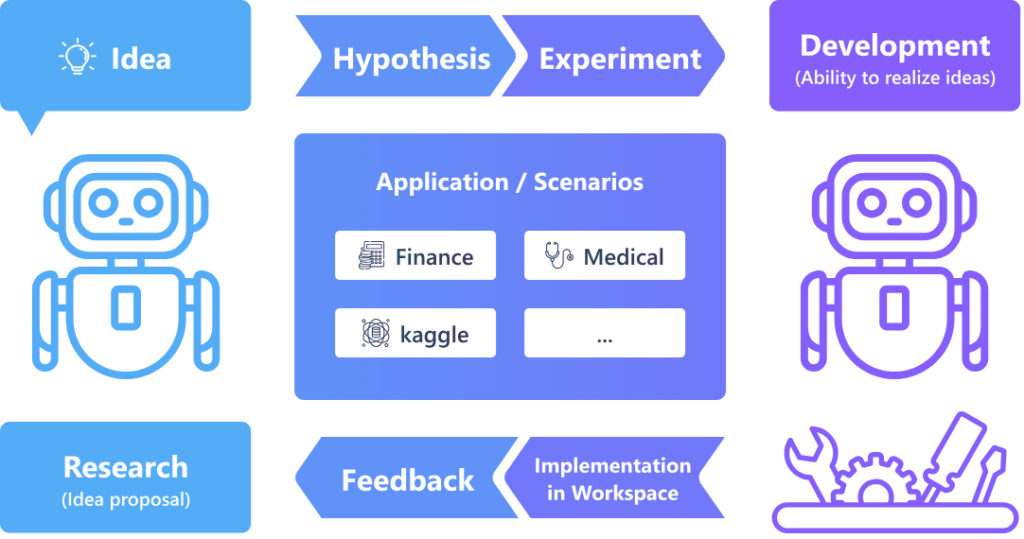
开发层面:高效实现并执行想法。开发过程的关键在于高效实现研究成果,同时通过合理的任务优先级调度来最大化效益。研究员们在 RD-Agent 框架中提出了面向数据中心任务开发的解决方案 Co-STEER。这一方法旨在处理从简单任务入手,通过学习不断提高的开发策略,并利用持续反馈优化整体开发效率。
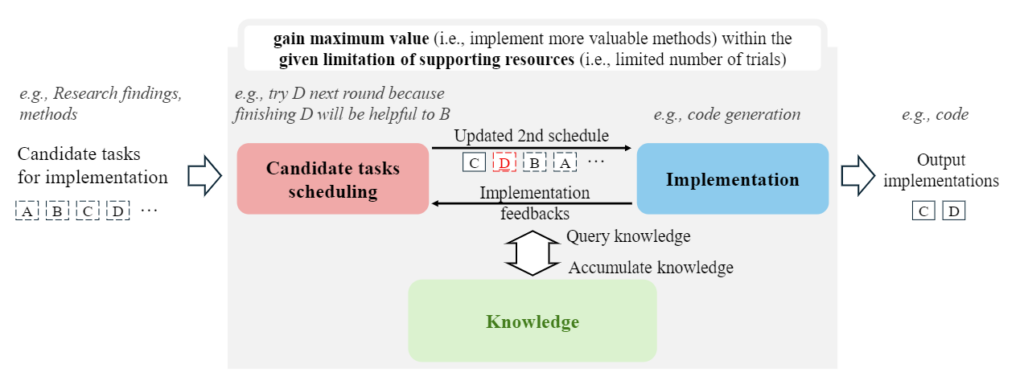
Co-STEER agent 通过不断进化的策略,积累特定领域的开发经验,不仅提高了任务调度的效率,还加速了开发能力的提升。Agent 开发水平不断增强,其反馈质量也随之提升,从而进一步优化调度算法,实现开发与调度的协同进化。

Co-STEER 论文:Collaborative Evolving Strategy for Automatic Data-Centric Development
https://arxiv.org/abs/2407.18690 (opens in new tab)
基准测试(Benchmark)层面:构建新的基准测试体系,评测 agent 的 R&D 能力。研究员们还开发了一个全新的基准测试集:RD2Bench。该基准测试涵盖了从数据构建到模型设计的一系列任务,用于评估大语言模型代理(LLM-Agent)在数据和模型研发方面的能力。
在评估模型开发能力时,研究员们从专注于模型结构设计的论文中抽取关键信息,并将实现细节通过数学公式和文本描述结合的方式提供给agent。在数据开发能力的评估中,研究员们选择了金融特征(因子)作为典型的高知识密集型场景,从公开的研究报告中抽取因子的实现公式和描述,用于研发agent的输入。针对所有任务,研究员们都实现了对应的正确版本,以此作为评估模型和数据构建结果的基础。

RD2Bench 论文:Towards Data-Centric Automatic R&D
https://arxiv.org/abs/2404.11276 (opens in new tab)
大语言模型的创新潜力有待进一步激发
展望未来,如何更高效地开展自动化数据科学研究仍是一个开放性问题,而如何充分激发大语言模型的创新潜力,实现跨领域乃至跨学科的知识迁移、融合与创新,更是当前面临的重要挑战。在开发过程中,如何自动化地理解反馈信息,并将其与现有的开发水平紧密结合,同时智能地调度任务、择优执行,以提升基础模型作为 agent 的能力,都是极具挑战且具有深远意义的研究方向。
要解决这些挑战,关键在于通过实践反馈促进研究与开发能力的同步提升,实现二者的协同进化。这种有机结合的方法将极大地提升大语言模型的创新能力,推动跨领域和跨学科的知识转移与创新,从而进一步提升研发效率与质量,真正实现自动化研究与开发的飞跃。
RD-Agent 体验链接:
https://aka.ms/RD-Agent (opens in new tab)
RD-Agent 视频 demo:
https://rdagent.azurewebsites.net/model_loop (opens in new tab)
https://rdagent.azurewebsites.net/factor_loop (opens in new tab)
https://rdagent.azurewebsites.net/report_factor (opens in new tab)
https://rdagent.azurewebsites.net/report_model (opens in new tab)