

Pushing the limit of semi-supervised learning with the Unified Semi-supervised Learning Benchmark
Neural models give competitive results when trained with supervised learning using sufficient high-quality labeled data. For example, according to statistics from the Paperswithcode website, recent traditional supervised learning methods can achieve an accuracy of over 88% on the ImageNet dataset, which contains millions of data. However, acquiring large amounts of labeled data is often time-consuming and labor-intensive.
To reduce reliance on labeled data, Semi-supervised Learning (SSL) aims to improve the generalization of the model by using a large amount of unlabeled data when there is only a small amount of labeled data.
Deep semi-supervised learning
Before deep learning, researchers in this field proposed classical algorithms such as semi-supervised support vector machines, entropy regularization, and co-training. With the rise of deep learning, deep SSL algorithms have also seen great progress, and tech giants have recognized the great potential of semi-supervised learning in practical scenarios. Google, for example, has used Noisy student training, an SSL algorithm, to improve its performance in searching [1]. The most representative SSL algorithms that currently exist usually use cross-entropy loss for training on labeled data and use Consistency Regularization on unlabeled data to encourage invariant predictions against input perturbations. For example, FixMatch[2] proposed by Google at NeurIPS 2020 uses Augmentation Anchoring and Fixed Thresholding techniques to enhance the generalization of the model to different strong augmented data and reduce noisy pseudo labels. During training, FixMatch filters out unlabeled data whose prediction confidence is lower than a user-provided/pre-defined threshold.
FlexMatch[3], proposed by Microsoft Research Asia and the Tokyo Institute of Technology at NeurIPS 2021, takes into account the different learning difficulties between classes. They proposed Curriculum Pseudo Labeling method to set different thresholds for different classes. Specifically, for easy classes, the model sets a high threshold to reduce the impact of noisy pseudo labels; for difficult classes, the model sets a low threshold to encourage the model to learn more on that class. The learning difficulty assessment for each class depends on the number of unlabeled data samples that fall into that class and are above a fixed threshold.
At the same time, they also proposed a unified Pytorch-based SSL codebase TorchSSL[4], which provides unified support for deep SSL methods, commonly used datasets and benchmark results in this field.
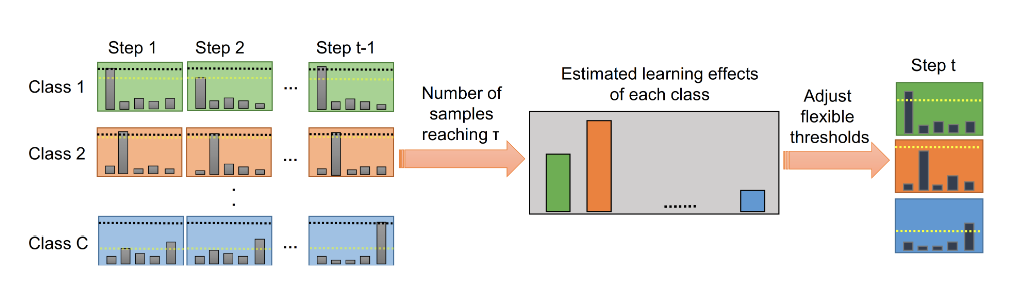
Current issues and challenges of the SSL codebase
Although the development of SSL is in full swing, we have noticed that most SSL papers focus only on computer vision (CV) classification tasks. Researchers in other fields (such as natural language processing (NLP) and Audio processing (Audio)) are unaware if these SSL algorithms can work in their areas as well. In addition, most SSL papers are being published by tech giants and not by academia. Laboratories in academia are often unable to jointly promote the development of semi-supervised fields due to limits in their computing resources. In general, SSL benchmarks currently suffer from the following two problems:
(1) Insufficient diversity. Existing SSL benchmarks are mostly constrained to computer vision (CV) classification tasks (i.e., CIFAR-10/100, SVHN, STL-10 and ImageNet classification), precluding consistent and diverse evaluation on classification tasks in NLP and Audio, and the lack of sufficient labeled data in NLP and Audio is also a common issue.
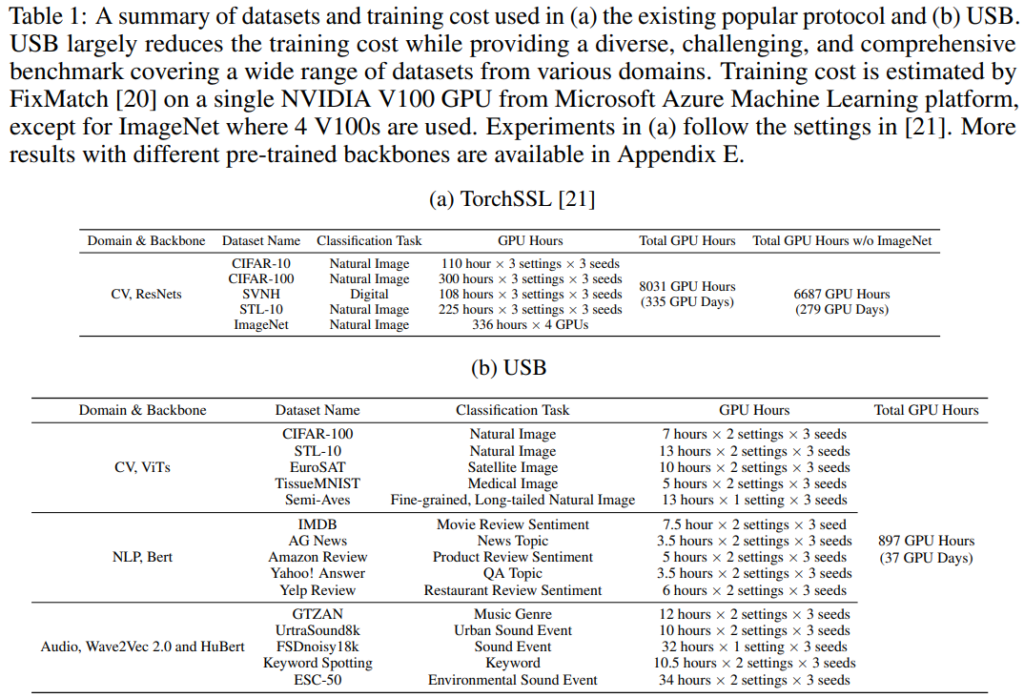
(2) Time-consuming and unfriendly to academia. Existing SSL benchmarks such as TorchSSL are often time-consuming and environmentally unfriendly as they require training deep neural network models, often from scratch. Specifically, it takes about 300 GPU days to evaluate FixMatch[1] with TorchSSL. Such high training costs make SSL-related research unaffordable for many research laboratories (especially in academia or small research groups), hindering the progress of SSL.
USB: a new more academia-friendly benchmark library with diverse tasks
Researchers from Microsoft Research Asia, in conjunction with researchers from Westlake University, the Tokyo Institute of Technology, Carnegie Mellon University, and the Max Planck Institute, proposed USB: the first Unified SSL Benchmark for CV, NLP, and Audio classification tasks. Compared with previous SSL benchmarks (such as TorchSSL) that only focus on a small number of vision tasks, USB not only introduces NLP and Audio, but also utilizes a pretrained vision model (Pretrained Vision Transformer) for the first time to greatly reduce the training cost of SSL algorithms (from 7000 GPU hours to 900 GPU hours), which makes SSL research more friendly to academia, especially for small research groups. The paper on USB has been accepted by NeurIPS 2022.

Paper:https://arxiv.org/pdf/2208.07204.pdf (opens in new tab)
Code:https://github.com/microsoft/Semi-supervised-learning (opens in new tab)
Solutions provided by USB
So how does USB solve the problems faced by current SSL benchmarks all at once? It does so by providing the following improvements:
(1) To enhance task diversity, USB introduces 5 CV datasets, 5 NLP datasets and 5 audio datasets to provide a diverse and challenging benchmark, enabling consistent evaluation on SSL algorithms across domains and tasks. The table below provides a detailed comparison of tasks and training time between USB and TorchSSL.
(2) To improve training efficiency, researchers introduced the pretrained Vision Transformer into SSL instead of training ResNets from scratch. It is found that using a pretrained model significantly reduces the number of training iterations (for example, it reduces the number of training iterations for CV tasks from 1 million steps to 200,000 steps) without hurting performance.
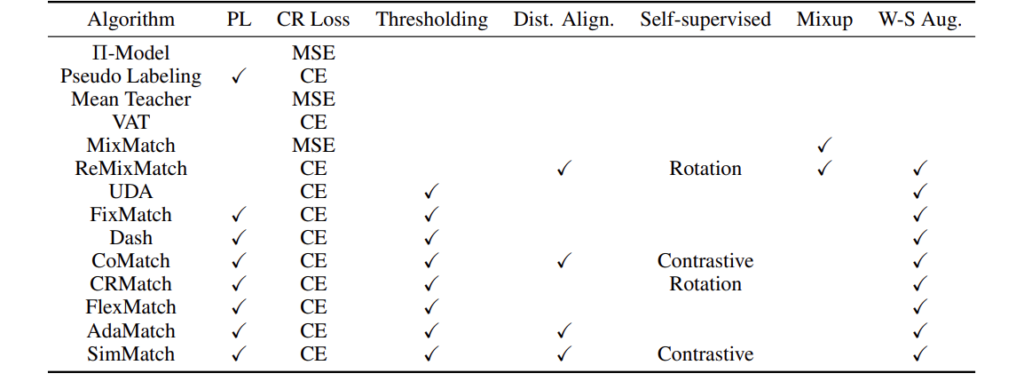
(3) To improve USB’s researcher friendliness, the research team open-sourced a modular codebase with 14 SSL algorithms and related configuration files for easy reproduction. To help users get started quickly, USB also comes with detailed documentation and tutorials. In addition, USB provides a pip package for users to directly use the SSL algorithm. Researchers hope to add new algorithms (such as imbalanced SSL algorithms, etc.) and more challenging datasets to USB in the future. The following figure shows the algorithms and modules already supported by USB.
Conclusion
SSL presents a promising direction for utilizing a large amount of unlabeled data to train more accurate and robust models. The research team hopes that USB can help academia and industry members make further progress in the field of SSL.
References
[1] https://ai.googleblog.com/2021/07/from-vision-to-language-semi-supervised.html (opens in new tab)
[2] Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems, 33:596–608, 2020.
[3] Bowen Zhang, Yidong Wang, Wenxin Hou, Hao Wu, Jindong Wang, Manabu Okumura, and Takahiro Shinozaki. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Advances in Neural Information Processing Systems, 34, 2021.
[4] TorchSSL: https://github.com/TorchSSL/TorchSSL (opens in new tab)