

By Xing Xie, Jianxun Lian, Zheng Liu, Xiting Wang, Fangzhao Wu, Hongwei Wang, and Zhongxia Chen
Information overload is a big challenge for online users. It is particularly an issue when a user has to quickly and accurately identify a resource from an exponentially growing set of information and products. It is also difficult for merchants to present the appropriate products to users in a timely manner. The emergence of the recommendation system has somewhat relieved this challenge.
A recommendation system is a type of information filter, which can learn users’ interests and hobbies according to their profile or historical behaviors, and then predict their ratings or preferences for a given item. It changes the way businesses communicate with users and strengthens the interactivity between them.
The statistics from studies by McKinsey and Tech Emergence bear this out: this type of recommendation system brought Amazon 35 percent of its revenue and 23.7 percent growth to BestBuy. Up to 75 percent of video consumption on Netflix comes from the recommendation system and 60 percent of views on YouTube come from their recommendation feature.
Therefore, how to build an effective recommendation system is of profound significance. What should the recommendation system of the future look like? Our research focuses on several aspects, such as the application of deep learning, knowledge graph, reinforcement learning, user profiling, and explainable recommendations.
Research topic 1: recommendation system and deep learning
In recent years, deep learning technology has achieved great success in areas of speech recognition, computer vision, and natural language processing; and recommendation systems can benefit from these breakthroughs. Today, deep learning-based recommendation algorithms have made remarkable progress in the following three aspects:
Powerful representation learning capability. One of the advantages of deep neural networks is their powerful capability in representation learning. Therefore, a direct application of deep learning for recommender systems is to learn meaningful latent factors from complex data sources.
Deep collaborative filtering. The conventional matrix factorization model can easily be interpreted as a simple neural network. In fact, we can incorporate additional non-linear units to further improve its performance. In one recent work (Neural Collaborative Filtering, WWW 2017), researchers propose an enhanced matrix factorization model. This model addresses the problem where the importance of different dimensions cannot be distinguished by the dot product between two vectors. This model requires an additional multi-layer perceptual module to carry out extra non-linear operations. Other examples of deep collaborative filtering include deep learning models such as auto-encoders, convolutional neural networks, memory networks, and attention mechanisms, all combined with the traditional collaborative filtering models and achieve remarkable improvements.
Deep interaction between features. In industrial applications, highly diverse and heterogeneous data are usually exploited and fused for achieving a better predictive performance. Traditional approaches to combining features are not scalable, are costly, and can’t be extended to new cases. Researchers are using neural networks to train high-order crossing features automatically. Representative works include Wide & Deep, PNN, DeepFM, DCN, and our recent proposed xDeepFM model (xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, KDD 2018).
Deep learning can be further applied to a great number of potential recommendation scenarios. Here is a brief discussion that highlights promising future directions.
- Efficiency and scalability. For industry-grade recommendation systems, people should not only consider a model’s accuracy, but also its running efficiency and maintainability. A recommendation system needs to return the result in real time, should be easily deployed, and should support regular incremental updates. Because the computational complexity of sophisticated neural networks is huge, making them more efficient and maintainable on super-large-scale platforms is imperative.
- Diversity data fusion. In the real-world, data for users and items is often complex and diverse. For example, the forms of data for an item can be text, images, and categorical properties. Behavioral data for users may also come from many fields, such as social networks, search engines, and online news apps. Behavioral data for users can also be diverse. For example, in e-commerce websites, their behavior may include searching, browsing, clicking, collecting, and purchasing. Moreover, for such different dimensions, the distributions of users or items are widely varied. For example, some items have only the attribute of text, while some others have only the attribute of image. Meanwhile, data volume might vary a lot, given different kinds of behaviors. For example, the volume of user clicks is often much larger than that of user purchases. Apparently, a single, homogeneous model cannot effectively handle such diverse data and effectively integrating complex data is technically difficult.
- The capture of users’ long- and short-term preferences. Users’ preferences can be roughly divided into long term and short term. Long-term preference refers to user’s natural interests which will show up eventually. Short-term preference refers to a user’s current or immediate interests and is prone to vanishing soon. Currently, some popular methods combine recursive neural networks with deep collaborative filtering technology as a method to integrate both short-term and long-term interests. Learning how to effectively incorporate the contextual states of users with their long-term and short-term interests is also a hot research topic.
Research topic 2: recommendation system and knowledge graph
In most recommendation scenarios, items may contain rich knowledge information. The network structure that captures such knowledge is referred to as the knowledge graph. The knowledge graph greatly expands the amount of information of each item and strengthens the connection between them, providing abundant reference values for a recommendation engine, which leads to additional diversity and explainability of the recommendation result (Figure 1).
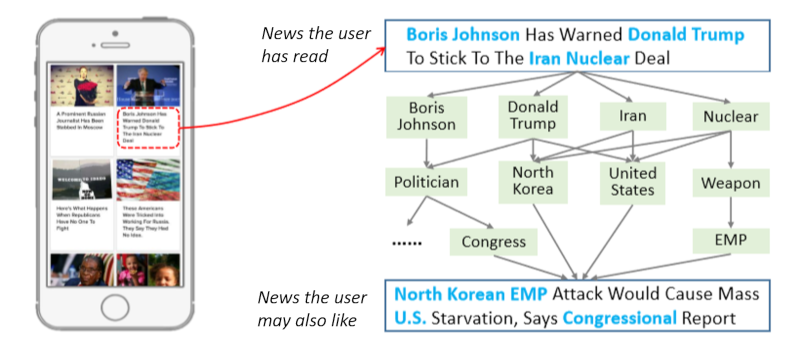
Figure 1. Relevance discovery of news reports, based on a knowledge graph
Compared to a social network, a knowledge graph is a heterogeneous network; therefore, more sophisticated recommendation algorithms are required. In recent years, network representation learning has become one of the most popular research areas for addressing this. The introduction of network representation will facilitate the learning capability of a recommendation system, thus contributing to a better recommendation accuracy and user experience.
There are two different ways of introducing a knowledge graph to a recommendation system.
The feature-based approach. The key technique for this approach is knowledge graph embedding (KGE). In general, a knowledge graph is a heterogeneous network composed by tuples in the form of
Under such a general framework, the learning of a recommendation system and KGE become two relative tasks. However, according to the differences of learning order, there are two combination strategies.
1) The sequential learning strategy, where features of the knowledge graph are learned first, and then applied to the recommendation system.
2) The alternating learning strategy, where training the KGE and the recommendation system become two related tasks. A multi-task learning framework is usually designed for it, where the learning of KGE significantly contributes to that of the recommendation system.
The structure-based approach. This approach uses the structural feature of the knowledge graph more directly. To be specific, for each specific entity, we may use the Breath First Search algorithm to get the recommendation results from the multi-hopped associated entities in the knowledge graph. Based on different ways of using the associated entities, the corresponding techniques can be divided into two categories: the one through outward propagation and the one through inward aggregation.
1) The outward propagation simulates the process when users’ interests propagate in the knowledge graph. As one of the representations of outward propagation, our recent work (RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems, CIKM 2018) aggregates the historical interests of users as seeds, and then propagates them iteratively along with the knowledge graph.
2) The inward aggregation aggregates an entity’s neighborhood features, while learning the knowledge graph. With cohesion computations, the entities incorporate the structural information of their neighborhood, whose weights are determined by the connectivity and specific users. Therefore, the semantic information of the knowledge graph and the individual interests of users can be captured simultaneously.
Opportunities and challenges of knowledge graph-based recommendation systems
The combination of a recommendation system with a knowledge graph is becoming one of the most popular topics in academia. However, the existing methods are limited in various aspects and there is still much room for improvement. First, most of the existing methods are based on statistical learning models, which extract statistical information from the network and make inferences accordingly. A difficult, but more promising direction, is integrating the graph reasoning with the recommendation system. Second, it is also interesting to design algorithms that produce competitive performance with economic running cost. Existing methods do not pay much attention to computational platforms, nor do they consider much about the coordination with systems and hardware, and so this opens up a third area of potential improvement. How to jointly design and optimize the upper-level algorithms and the underlying architecture will be another crucial issue. Finally, the existing methods are always static; whereas, in reality, the knowledge graph evolves over time. As a result, it is also important to think about how to cope with such temporal evolvement and make use of it for better recommendations.
Research topic 3: recommendation system and reinforcement learning
Empowered by the latest techniques on deep learning and the knowledge graph, recommendation systems have been increasing in performance. However, most of the existing recommendation systems are formulated in a one-way fashion: given sufficiently collected historical data, a specific type of supervised learning model (such as linear regression or factorization machine), is trained to capture the underlying preferences of users over difference kinds of items. Once deployed online, the well-trained model can identify the most attractive items for its users, thereby generating the personalized recommendation precisely. In this place, it is assumed that the behavioral characteristics of users have been fully reflected from the historical data; meanwhile, they will always remain stable over the time. As a result, a static model will be sufficient for practical usage. However, user data might be limited in practice, and characteristics of users may constantly evolve during their intensive interaction between recommendation systems. Fortunately, the user feedback generated in such a process will not only complement any insufficiency of the historical data, but also help to uncover user characteristics for the current stage. Reinforcement learning lays the technical foundation for utilizing user feedback for a recommendation system. In the following section, applications of the reinforcement learning-based recommendation system are individually discussed for both static and dynamic scenarios, according to the different behavioral characteristics of users.
Application in the static scenario
Under the static scenario, user behavior is regarded as unchanging. For these kinds of situations, some of the most notable work is the contextual multi-armed bandit, which aims to address the cold-start problem in recommendation systems. For many real-world applications, user behavior follows long-tailed distribution, that is, little behavioral data is collected for the majority of users, while only a small fraction of users offer substantial records. As a result, it is hard for the conventional recommendation algorithms to generate satisfactory performances, due to data sparsity.
A straightforward idea to deal with the cold-start problem is that of “active exploration”—instead of accumulating user data in a passive way, the recommendation system actively detects the behavioral patterns of users through continuous trials, such that the collected data will be sufficient to guarantee the effectiveness of recommendations. Unfortunately, such a simple approach will inevitably incur tremendous exploration and user time cost, which makes it infeasible in practice. With inspirations from the multi-armed bandit problem, we can strategically explore recommendations based on user feedback, making it much more competitive in terms of cost-effectiveness. The multi-armed bandit problem has been intensively studied, where all the proposed algorithms share the common principle of jointly considering both utility and cumulative trials. Higher utility indicates lower exploration costs, while lower cumulative trials suggest higher uncertainties. As a result, we can design specific aggregation mechanisms which prioritize the items with high recommendation utility and uncertainties.
Application in the dynamic scenario
One of the inherent assumptions of the multi-armed bandit is that the user’s underlying character will always remain stable. However, for many real-world scenarios, the behavioral patterns of users evolve constantly. As a result, it is necessary to conduct precise estimation about such evolution, and then optimize the recommendation strategy on top of it. Particularly, an ideal recommendation system should satisfy the following two requirements: the recommendations should be based on the constantly evolving feedback data of users and specific types of long-term objectives need to be optimized over the whole interactive process.
Under the framework of reinforcement learning, the recommendation system is regarded as an agent that aims to optimize the predefined long-term objective through its strategic interaction with users. User characteristics are treated as a state and specific recommendation items become actions of the agent. The behavioral data generated from the interaction is organized as experience, which records the reward and state-transition resulting from a certain action. Based on the constantly accumulated experience, the reinforcement learning algorithm produces the policy, which then guides the optimal action selection given each specific state.
Recently we applied reinforcement learning to Bing personalized new recommendation (DRN: A Deep Reinforcement Learning Framework for News Recommendation, WWW 2018). Thanks to the capability of sequential decision making and long-term objective optimization, reinforcement learning algorithms can greatly enhance a recommendation system’s capability for both user perception and personalization.
Opportunities and challenges of the reinforcement recommendation systems
We expect the research community to be working on many technical advancements in reinforcement learning-based recommendations. For one, helping reinforcement learning algorithms to adapt to limited data sets. Today, mainstream deep reinforcement learning algorithms try to avoid modeling the environment, and instead try to learn policy directly from the user experience (model-free). However, such a strategy requires a considerable amount of empirical data that is typically limited in scale and sparse in reward. How to fully take advantage of limited user interactions will be one of the major directions for the algorithm’s further improvement.
Second, a policy is usually learned independently for each individual recommendation scenario and policies from different scenarios are typically different. As a result, each policy learning process requires a considerable data collection expense. Meanwhile, due to the lack of generalizability, it is difficult for existing algorithms to adapt their policies in response to newly emerging situations. Given the above challenges, it is necessary to come up with a highly generalized strategy that breaks down the barriers between different recommendation scenarios and increases its robustness in the changing environment.
Research topic 4: user profiling in recommendation systems
One of the important tasks of building a recommendation system is analyzing the characteristics of users’ interests. This is often referred to as user profiling.
User profiling refers to the extraction of user labels on different attributes such as age, gender, occupation, income, and interests. Complete and accurate attribute labels will effectively reveal the inherent characteristics of users, thus greatly facilitating accurate personalized recommendations.
Current status and challenges in user profiling
Currently, mainstream approaches to user profiling are based on machine learning, especially supervised learning. These methods extract features from user data, which serve as the user’s representations. User data, together with its annotations, are used to train the prediction functions of a user’s profile, from which we can infer the profiles of many users whose profile labels are unknown.
Although current user profiling methods have achieved good results and are widely applied to real-world recommendation systems, a number of challenges remain to be addressed.
First, most of the existing methods are based on manually extracted discrete features. These features cannot capture contextual information about the user, which restricts their representational capacity.
Second, existing user profiling methods are usually based on simple linear regression or classification models, so they can neither automatically learn the high-level abstracted features from user data, nor model the interaction between features. In addition, existing methods for user profiling are often based on homogeneous data from one source, which is not rich enough for effective representation of users. In fact, user data many come from different sources, which can help build higher-quality user profiling.
Finally, few of the existing methods for user profiling take time into their consideration, so it is difficult to reflect the dynamic changes of user attributes.
Deep, universal, and dynamic user profiling from multi-source heterogeneous data
In response to the above challenges, researchers are working on the following user profiling directions.
1) Building user representation models with stronger representation capability. With the development of deep learning, neural networks can automatically extract deep and informative features from a user’s original data. Based on the deep neural network, we can construct representations with the full use of user data, thus effectively improving the accuracy of user profiling. Recently we developed a hierarchical user representation with attention (Neural Demographic Prediction using Search Query, WSDM 2019), which is shown to be effective in inferring user demographics based their query logs.
2) Conducting user profiling on multi-source and heterogeneous data. The data generated by users is usually rich in form, exhibiting different structures (such as unstructured text data from social media and structured purchase records from e-commerce websites), and represented in different modes (such as text and images), which is a challenge for user profiling. Designing a deep information fusion model to employ user data from different sources, structures, and modes for user profiling is an important direction in the future. Collaborative learning and multi-channel deep neural networks can be the potential solutions for relevant problems.
3) Sharing the user data across different platforms and protecting user privacy. Different platforms record different types of user data. For example, search engines have users’ search logs and web browsing records are tracked by search engines, while the e-commerce platforms have users’ commodity browsing and shopping behaviors. User data from different platforms are of great value for user profiling, providing complementary information and helping to build richer and more comprehensive user representations. How to make full use of user information from different platforms, without explicit transferring or sharing of private user data, is an important issue to work on.
4) Constructing a unified user representation model for user profiling. Existing user profiling methods often train an individual model for each user attribute. However, in practice, the number of user attributes can be huge. Therefore, existing user profiling methods often involve a great deal of model training and storage. In addition, the underlying connections between different user attributes are yet to be fully explored. Can we find a way to build a unified user representation from the heterogeneous data, such that the model can comprehensively capture the information of a user from different dimensions? The multi-task learning-based learning algorithms and user-embedding technologies provide promising solutions for such a problem.
Research topic 5: explainable recommendation system
A recommendation system whose results can be easily explained and that uses examples will be more likely to capture the user’s attention. Current research finds that such a system will not only improve the system’s transparency, but also increase the user’s trust and acceptance of the system, thus facilitating the user’s selection of the recommended products and improving user satisfaction. As a result, designing an explainable recommendation system will be our ultimate goal.
Opportunities and challenges of the explainable recommendation system
As a comparatively fresh issue in the field of recommendation systems, many aspects of explainable recommendations are worthy of exploration. We are presently considering future research directions for the following three aspects.
Enhancement of the explainability by knowledge graph. As an external knowledge carrier with high readability, the knowledge graph brings a great opportunity to improve the explanation of the algorithm. The existing recommendation explanations are usually limited to one of three forms: item-mediated, user-mediated, or feature-mediated. We expect to use a knowledge graph to build connections between these three forms and flexibly choose the most suitable one for a user’s explanation for a specific situation. In addition, we may also use concept graphs, such as Microsoft Concept Graph, to establish the deep readable structure between features and thus equip the current deep neural network with both readability and accuracy.
In an era where artificial intelligence is becoming more and more important, the combination of symbolic knowledge from a knowledge graph and deep learning is a promising research direction.
Model-agnostic explainable recommendation framework. At present, most explainable recommendation systems are designed for specific recommendation models with limited extensibility. For emerging recommendation models, such as the complex and mixed models using deep neural networks, the explainable capability is usually insufficient. Once there is a model-agnostic explainable recommendation framework, we can avoid designing the explanation schemes for different recommendation systems—thus improving their extensibility. One recent work proposed by our group (A Reinforcement Learning Framework for Explainable Recommendation, ICDM 2018) makes a preliminary effort in this direction. In this work (Figure 2), a reinforcement learning framework is designed for the recommendation model’s explanation, and it exhibits superior extendibility, explainability, and explanation quality.
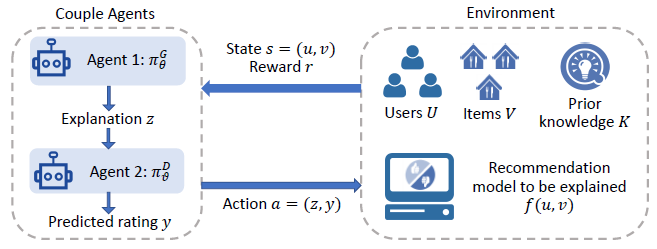
Figure 2. Framework of the model-agnostic reinforcement explainable recommendation
Conversational explainability based on generative models. Current explanations for recommendations tend to be inflexible and monotonous (for example, explanations are preset to be user-mediated). Although current systems can generate useful explanations, they are still too rigid in terms of how they communicate. If the recommendation system can create some natural and emotional words via generative models, the recommendation can be explained flexibly when chatting with users. In our collaboration with Microsoft Xiaolce, we have made efforts to generate explainable music recommendations through chatting.
A recommendation system of high efficiency and extendibility is imperative in the future; meanwhile, we expect advances in the incorporation of heterogeneous data and the perception of the long- and short-term interests of users. The exploitation of the knowledge graph, the design of generalized learning mechanisms, and making full use of interactive data will be the most important research directions in the coming few years. We also need to pay close attention to explainability, which will require integrating the knowledge graph, the collaboration with reinforcement learning, the design of model-agnostic algorithms, and the incorporation of generative models. Last, but not least, user privacy should never be ignored as we move toward data-sharing mechanisms and a unified user representation across different platforms.
We believe that personalized recommendation systems will continue to develop in various directions, including effectiveness, diversity, computational efficiency, and explainability; and that this will ultimately address the problem of information overload.