

Trustworthy data and analyses are key to making sound business decisions, particularly when it comes to A/B testing. Ignoring data quality issues or biases introduced through design and interpretations can lead to incorrect conclusions that could hurt your product.
In the 14+ years of research since we launched our internal Experimentation Platform, we have enabled and scaled A/B testing for multiple Microsoft products, each with their own engineering and analysis challenges. One common need that each of our partner teams demands: trustworthiness. If experiment results cannot be trusted, engineering and analysis efforts will be wasted and organizations will lose — you guessed it — trust in experimentation. Therefore, ensuring trustworthy experiments remains a top challenge across the industry [9].
There have been a lot of tools and techniques developed to improve trustworthiness in A/B testing, covering various practical aspects from broad overview of experimentation systems and challenges [1]–[3], to having a right overall evaluation criteria [4]–[8], pitfalls in interpretation of experiment results [9][10] and designing metrics [7][11].
But how can we ensure such trustworthy A/B testing end-to-end?
In this series of blogposts, we aggregate and describe a comprehensive list of experiment design and analysis patterns used within Microsoft to increase confidence in the results of A/B testing. These patterns help automatically detect or prevent issues that would affect the trustworthiness or generalization of experiment results. Consequently, feature teams can confidently make a ship/no-ship decisions based on the observed results and learn from them for future development.
We divide these patterns into three major categories to track the lifecycle of an A/B experiment: the pre-experiment stage, the experiment monitoring and analysis stage, and the post-experiment stage.
In the first part of the series, we focus on the pre-experiment stage and start with the most basic step in A/B testing: formulating the hypothesis of the A/B test.
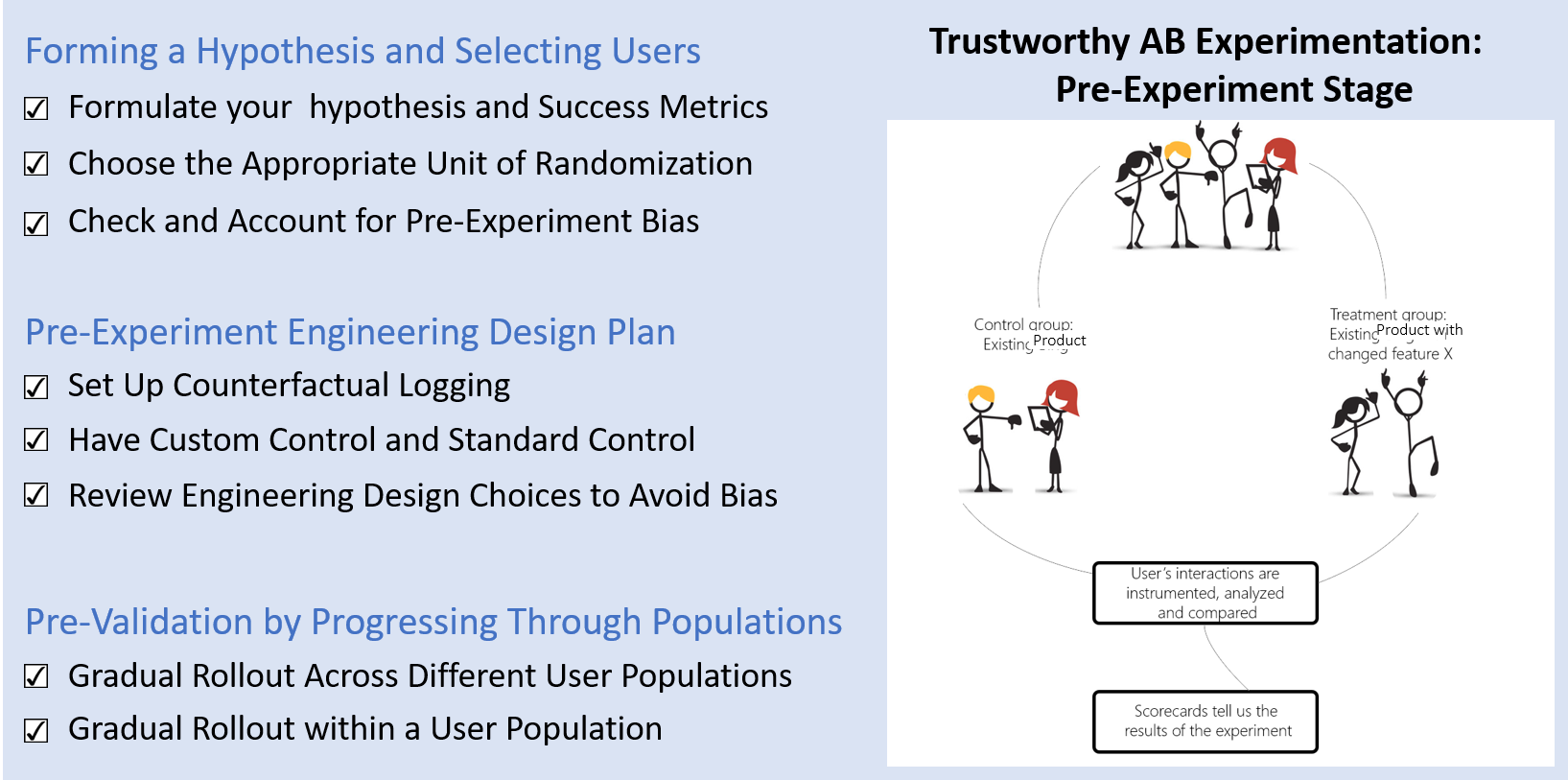
Pre-Experiment Trustworthiness Patterns. Illustration c/o Ilda Ladeira
Forming a Hypothesis and Selecting Users
Formulate your Hypothesis and Success Metrics
The first step in designing an A/B experiment is to have a clear hypothesis. The hypothesis should capture the expected effect of the change introduced by the treatment. It should also be simple: If you are making a complex change, break it down into a series of simple changes – each with its own hypothesis. Then you will be able to measure the impact of each individual component.
The hypothesis should also include a set of metrics to measure the impact of the change introduced on the product. Note that the hypothesis should be falsifiable or provable by the set of metrics considered. For example, a hypothesis claiming that a certain treatment will improve branding is hard to prove or falsify if there is no metric that can quantify the impact of the brand.
Choosing the right set of metrics for the experiment is essential to get a correct measurement of the treatment effect. A core set of metrics should contain user satisfaction metrics, guardrail metrics, feature and engagement metrics and data quality metrics [11]. These metrics should be computed for all experiments in a product, regardless of which features they target. This guarantees that we can always detect regressions of important metrics, regardless of which feature we are testing on. We will cover metric design in an upcoming blogpost.
Another important consideration when forming the hypothesis is the power of the A/B test to detect the anticipated change in the metrics [12]. Note that power calculation sets a lower bound on the number of randomization units that will be directly affected by the A/B test. If we anticipate that only a small proportion of the traffic will be affected, we need to assign an amount of traffic to the A/B test that ensures the affected portion satisfies the power calculation lower bound.
Choose the Appropriate Unit of Randomization
Different flavors of user identifiers (Id) are often used as a randomization unit. Be aware of their limitations and know when a certain identifier is not suitable for your experiment. Below are three considerations we use at Microsoft when choosing the randomization unit.
Stability of the Id: On the web, users are tracked using cookie-based Ids. Such ids are easy to implement and track, however they are not stable. Users can clear their cookies and land in the other variant in the next visit, making accurate estimation of long term effects of a treatment hard [13]. Only use such ids for short-term experiments to avoid having your experiment population significantly churned. Moreover, create metrics to capture the various categories of cookies used for tracking to ensure that the treatment is not affecting them disproportionately compared to control.
Network Effects: When product changes impact both the user and their collaborators/connections, the stable unit treatment value assumption (SUTVA) [14] – that each user’s response in the experiment is independent of the treatment assignment to other users – is violated. Experimenting with such features is an active area of research. Common successful methods usually include randomization at a cluster level [15] which produces a different and unbiased estimate compared to simple user level randomization [16].
Enterprise Constraints: Product and business limitations can constrain the selection of the randomization unit. They might require that a feature is deployed to the entire enterprise for full effectiveness, or the admins in an enterprise may have a policy to deliver a uniform experience to all users. In such cases it is not possible to randomize by individual users. Randomizing at the enterprise-level brings up special considerations to be aware of [17].
Pay attention to the choice of the randomization unit for the A/B test. All identifiers have some limitations and we cannot test all features with a single randomization unit. Having the ability to randomize by various identifiers depending on the hypothesis of the test will allow feature teams to correctly measure the impact of their features and trust the experiment results.
Check and Account for Pre-Experiment Bias
We recently tested a new change for Edge browser in an experiment. The feature was changing the format in which some data is stored internally and was expected to have no user facing impact. But the experiment analysis showed a degradation in a key user engagement metric with a p-value of 0.01. There was no clear reason why the feature would cause such a regression and there was no movement in other metrics that could explain the regression. One could conclude that the metric movement is a false positive and let the feature ship, but how can we be sure? We could re-run the experiment. However, re-running takes time, impacting experimentation agility and in some cases, it might not be feasible.
How can we reduce the chance of false positives and increase our confidence that the observed metric movements are due to the treatment? It turns out historical data can be very useful for detecting and mitigating pre-experiment bias. Below are three techniques that we employ at Microsoft:
Retrospective-AA Analysis: This analysis computes the same metric for the treatment and control group in the period before the experiment start. We check if there was any bias between treatment and control group in the pre-experiment period metric. If we do observe a significant difference in a metric between the two variants in the Retro-AA analysis, we are more confident that a statistically significant movement (with p-value close to 0.05) in the metric in the experiment period is likely due to the bias introduced by randomization. Retro-AA analysis is not a conclusive test of bias in a metric due to randomization, but it is a very useful indicator in the absence of other evidence suggesting otherwise.
Seedfinder [1]: While Retrospective-AA analysis helps in identifying some false positive in the results of the A/B test, it is a lagging indicator of bias. Can we reduce chances of having that bias before starting the experiment? That’s where Seedfinder [1] comes in. Typically, for any A/B experiment, we use a hash function and a seed to randomize users to the different variants in an experiment. With Seedfinder, before starting the experiment, we generate a key set of metrics for a large number of seeds. Then we pick an optimal seed, the one where we observe the least amount of statistically significant metric differences. We suggest generating a couple hundred seeds, but the number can vary based on the product and metrics chosen. Such re-randomization reduces the noise in metrics that is unrelated to the treatment tested and improves the precision of the estimated treatment effect [18].
Variance Reduction [19]: Using pre-experiment period data for the same metric can help reduce both bias and variance in the final analysis. This method is commonly employed for variance reduction(VR) [19][20] to get improved sensitivity for a metric. The basic idea of VR is to use the metric in the pre-experiment period to reduce the variance in the metric during the experiment. At Microsoft, VR plays a vital role in increasing the sensitivity of our metrics. For example, this technique was used in experiments involving multiple top-level metrics for Bing and MSN that are typically noisy and hard to move in a statistically significant way. The same metrics without this method remained flat, giving a wrong impression that the change being tested is not adding value.
In general, we recommend using a combination of all three techniques to improve the trustworthiness of experiment results. Use Seedfinder to find a randomization that does not indicate a bias in key metrics in the pre-experiment period. Variance reduction increases metric sensitivity and reduces bias, while Retrospective-AA analysis helps you investigate movements in other metrics that were not optimized by Seedfinder [21].
Pre-Experiment Engineering Design Plan
The next set of patterns cover some engineering practices done before the experiment starts that we employ at Microsoft to increase trustworthiness of our experimentation.
Set Up Counterfactual Logging
When running A/B test, not every user in the two variants will be exposed to the treatment. Some changes target users with a specific intent or behavior. For example, consider the weather forecast answer in Bing. When it was first developed, the team wanted to run an A/B experiment to test its effect on user behavior. When we first analyzed the results, we weren’t able to detect any statistically significant movements in the desired metrics. It turns out only a small portion of the users in the test issue a weather-intent query and see the weather answer. The largest portion of the users in the test never issued any queries with weather-intent and those users’ logs simply add noise, overpowering the signal from the small portion of users who were in fact affected by the weather forecast answer.
What we need is a scorecard that “zooms in” to the portion of users who issued queries with weather intent. But how can we identify them? On treatment, it is relatively straightforward: find all users for whom Bing served the weather forecast answer. How can we identify such users in control? Bing didn’t show any weather answer on control since the answer is not in production yet. This is where counterfactual logging comes in: for each control variant request sent to Bing, the system determines whether it would have shown the weather answer if the user was assigned to treatment instead of control. If the answer would have shown, it will be marked in that impression’s log entry – we call that the counterfactual flag.
Counterfactual logging enables us to identify the exact same type of traffic from treatment and control, so that we can make an apples-to-apples comparison between the two variants. It allows us to identify the portion of users that were or would have been affected by the change on both treatment and control. Now we can perform a more sensitive analysis that remove noise from unaffected users and allow us to detect statistically-significant movements in the metrics. Note that it’s important to check the correctness of the counterfactual logging to avoid missing affected users from our zoomed-in scorecard. Checking for Sample Ratio Mismatches (SRM) [10] is one of the easiest way of doing that.
Running both treatment and control systems for each impression can be computationally inefficient and can cause delays that would negatively affect the user’s experience. In practice, there are many optimizations that can be introduced, and they depend on the implementation details of the system: not running the counterfactual logging on the critical path, setting it up only for the feature tested as opposed to the full product stack, or making the counterfactual flag too permissible and hence including some unaffected users in the analysis if it leads to a faster or cheaper implementation.
Have Custom Control and Standard Control
Feature teams at Microsoft sometimes need to create a custom control that is specific to an experiment (counterfactual logging, which we discuss above, necessitates a custom control). However, relying only on the custom control to assess the treatment effect can lead to untrustworthy results.
Microsoft News once ran an experiment where the treatment was making a minor tweak to the UI on their page. A common configuration system was used to configure both treatment and control variants in this experiment. Due to an error in specifying the configuration, both treatment and control experiences did not have the search box on the new tab page. This caused a massive impact on user satisfaction and engagement but since the error impacted both treatment and control there was no detectable change when comparing treatment to control. The change was detected only when we compared treatment to production users, as part of a standard control. Users who are part of the standard control do not get exposed to any code from the experiment. We can now test if the code added to the custom control is causing a large movement in our metrics by comparing the standard control to custom control, indicating a problem in the custom control. This allowed us to shut down the experiments quickly to prevent further harm to users.
Note that implementation of standard control for all experiments at scale is not trivial. It should be designed to not exhaust significant amount of traffic, keep users in certain experiments isolated [1][12][22], and respect the traffic settings targeted by each experiment.
Review Engineering Design Choices to Avoid Bias
When setting up the data pipelines and the infrastructure used by each variant in an A/B test, make sure that none of these design decisions impact how treatment and control responses are returned, unless they are intended to be part of the treatment.
This issue comes up frequently when the treatment is testing a new or improved machine learned model. If any components of the machine learned model are shared between treatment and control, then any update to the machine learned model based on such shared components will impact both treatment and control. We can expect control to start showing some of the more relevant content that initially appeared in treatment alone. This artificially improves the control experience due to the leakage of treatment effect and introduces a bias in the estimation of the treatment effect. Such components can be features of the model, the data pipeline used for training, or the model itself.
Other engineering design decisions can also lead to one of the variants being at an unintended advantage. Consider for example how Bing serves results to queries issued by the user. For a faster response, the system might have some responses available in a cache to reduce the response time. The size of the cache and whether or not it is a shared resource between treatment and control can unintentionally affect any performance comparison between the two.
In the experiment design stage, examine your architecture and engineering decisions to avoid leakage of treatment effect through shared infrastructure or giving one of the variants an advantage by not controlling for availability of resources or other relevant factors.
Pre-Validation by Progressing Through Populations
While every change to a product will go through a rigorous quality control process before it is exposed to users, there is still a large amount of uncertainty about the desirability of the change. The more users we can include in the experiment the more we can reduce uncertainty. This introduces a tradeoff between risk and certainty. If a change is indeed not desirable, exposing it to a large number of users will increase the cost. However, if the change is not introduced to a large enough number of users, we may not know that the change is not desirable due to low statistical power to detect sufficiently small changes. Our solution is to perform a safe rollout [23] where the treatment is tested gradually across various user populations or rings, and gradually increasing percentages within a user population.
Gradual Rollout Across Different User Populations
One way to navigate the risk v/s certainty tradeoff is to test a change in a special user population – say dogfood or beta users- before testing the change in a more general and bigger population. Testing a change in a dogfood user population can help identify egregious functional and experience issues before exposing this change to more general users. This early test reduces the uncertainty about the treatment effect: if a change will cause a large regression in the dogfood population, it is also likely to cause a regression in the general population as well. We do strongly advise against concluding that the results from an experiment on dogfood audience will apply exactly on the general population. Experiments in dogfood audiences should just be used as a milestone leading to experiment in general population.
Gradual Rollout within a User Population
Once we decide to experiment with the general user population, another way to navigate the risk v/s certainty tradeoff is to only expose a small portion of that population to the treatment and ramp-up as we observe and measure the treatment effect. An experiment can be first exposed to 1% of the traffic and gradually ramped-up to 5%, then 10% until the desired final traffic is achieved. With each ramp-up, we compute metrics for each traffic percentage to measure the treatment effect on the user: as the traffic increases, the power increases and we will be able to detect any unanticipated regressions in the metrics we care about.
With such progressions between user populations and within the same population, we can gradually test a treatment and detect any unintended consequences without causing unnecessary harm to the user experience.
Applying these pre-experiment patterns can help you to start your A/B experiment confident that you reduced untrustworthiness and bias in your data. Next time, we will cover experiment monitoring and analysis patterns to carry trustworthiness through the experiment period.
– Widad Machmouchi, Somit Gupta, Ruhan Zhang, Aleksander Fabijan, Microsoft Experimentation Platform
References
[1] S. Gupta, L. Ulanova, S. Bhardwaj, P. Dmitriev, P. Raff, and A. Fabijan, “The Anatomy of a Large-Scale Experimentation Platform,” in 2018 IEEE International Conference on Software Architecture (ICSA), Apr. 2018, no. May, pp. 1–109, doi: 10.1109/ICSA.2018.00009.
[2] R. Kohavi et al., “Online experimentation at Microsoft,” Third Work. Data Min. Case Stud. Pract. Prize, pp. 1–11, 2009, doi: 10.1002/adfm.200801473.
[3] S. Gupta, R. Kohavi, D. Tang, and Y. Xu, “Top Challenges from the first Practical Online Controlled Experiments Summit,” ACM SIGKDD Explor. Newsl., vol. 21, no. 1, pp. 20–35, 2019, doi: 10.1145/3331651.3331655.
[4] P. Dmitriev and X. Wu, “Measuring Metrics,” in Proceedings of the 25th ACM International on Conference on Information and Knowledge Management – CIKM ’16, 2016, pp. 429–437, doi: 10.1145/2983323.2983356.
[5] R. Kohavi, A. Deng, B. Frasca, R. Longbotham, T. Walker, and Y. Xu, “Trustworthy online controlled experiments: Five Puzzling Outcomes Explained,” in Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining – KDD ’12, 2012, p. 786, doi: 10.1145/2339530.2339653.
[6] A. Deng, P. Dmitriev, S. Gupta, R. Kohavi, P. Raff, and L. Vermeer, “A/B testing at scale: Accelerating software innovation,” 2017, doi: 10.1145/3077136.3082060.
[7] A. Deng and X. Shi, “Data-Driven Metric Development for Online Controlled Experiments,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining – KDD ’16, 2016, pp. 77–86, doi: 10.1145/2939672.2939700.
[8] K. Rodden, H. Hutchinson, and X. Fu, “Measuring the User Experience on a Large Scale : User-Centered Metrics for Web Applications,” Proc. SIGCHI Conf. Hum. Factors Comput. Syst., pp. 2395–2398, 2010, doi: 10.1145/1753326.1753687.
[9] P. Dmitriev, S. Gupta, D. W. Kim, and G. Vaz, “A Dirty Dozen: Twelve common metric interpretation pitfalls in online controlled experiments,” in Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017, vol. Part F1296, pp. 1427–1436, doi: 10.1145/3097983.3098024.
[10] A. Fabijan et al., “Diagnosing sample ratio mismatch in online controlled experiments: A taxonomy and rules of thumb for practitioners,” Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., pp. 2156–2164, 2019, doi: 10.1145/3292500.3330722.
[11] W. Machmouchi and G. Buscher, “Principles for the design of online A/B metrics,” 2016, doi: 10.1145/2911451.2926731.
[12] R. Kohavi et al., “Controlled experiments on the web: survey and practical guide,” Data Min Knowl Disc, vol. 18, pp. 140–181, 2009, doi: 10.1007/s10618-008-0114-1.
[13] P. Dmitriev, B. Frasca, S. Gupta, R. Kohavi, and G. Vaz, “Pitfalls of long-term online controlled experiments,” Proc. – 2016 IEEE Int. Conf. Big Data, Big Data 2016, pp. 1367–1376, 2016, doi: 10.1109/BigData.2016.7840744.
[14] G. W. Imbens and D. B. Rubin, Causal Inference for Statistics, Social, and Biomedical Sciences. Cambridge University Press, 2015.
[15] P. Goldsmith-Pinkham and G. W. Imbens, “Social Networks and the Identification of Peer Effects,” J. Bus. Econ. Stat., vol. 31, no. 3, pp. 253–264, Jul. 2013, doi: 10.1080/07350015.2013.801251.
[16] M. Saveski et al., “Detecting Network Effects: Randomizing Over Randomized Experiments,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017, pp. 1027–1035, doi: 10.1145/3097983.3098192.
[17] S. Liu et al., “Enterprise-Level Controlled Experiments at Scale: Challenges and Solutions,” in Proceedings – 45th Euromicro Conference on Software Engineering and Advanced Applications, SEAA 2019, Aug. 2019, pp. 29–37, doi: 10.1109/SEAA.2019.00013.
[18] K. L. Morgan and D. B. Rubin, “Rerandomization to improve covariate balance in experiments,” Ann. Stat., vol. 40, no. 2, pp. 1263–1282, Apr. 2012, doi: 10.1214/12-AOS1008.
[19] H. Xie and J. Aurisset, “Improving the Sensitivity of Online Controlled Experiments,” Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. – KDD ’16, pp. 645–654, 2016, doi: 10.1145/2939672.2939733.
[20] A. Poyarkov, A. Drutsa, A. Khalyavin, G. Gusev, and P. Serdyukov, “Boosted Decision Tree Regression Adjustment for Variance Reduction in Online Controlled Experiments,” Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. – KDD ’16, pp. 235–244, 2016, doi: 10.1145/2939672.2939688.
[21] R. Kohavi, “Twyman’s Law.” .
[22] D. Tang et al., “Overlapping experiment infrastructure,” in Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining – KDD ’10, 2010, p. 17, doi: 10.1145/1835804.1835810.
[23] T. Xia, S. Bhardwaj, P. Dmitriev, and A. Fabijan, “Safe Velocity: A Practical Guide to Software Deployment at Scale using Controlled Rollout,” in 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), May 2019, pp. 11–20, doi: 10.1109/ICSE-SEIP.2019.00010.