

作者:系统组(上海)
编者按:基于大语言模型(LLMs)开发的应用目前主要使用公共 LLMs 服务提供的 API 进行,但是这些 LLMs 服务的 API 设计以请求为中心,缺乏应用级信息,难以有效优化整个应用流程,影响任务的端到端性能。为此,微软亚洲研究院的研究员们开发了一个专注于 LLMs 应用端到端体验的服务系统 Parrot,它具有减少网络延迟、提高吞吐量、减少冗余计算等优势。Parrot 可以通过引入语义变量,向公共 LLMs 服务公开请求间关系,从而开辟了 LLMs 应用端到端性能优化的空间。相关论文已被计算机系统领域顶级学术会议 OSDI 2024 收录。
大语言模型(LLMs)以其卓越的语言理解能力引领了一场应用开发领域的范式转变。在新兴范式中,一个或多个应用实体,被称为 AI 代理(AI agent)或 AI 智能副驾驶(AI co-pilot),通过自然语言(即“提示词”prompt)与 LLMs 进行交流,以协作完成一项任务。这种协作方式使得基于 LLMs 的应用程序能够通过一系列精心设计的对话流程,实现任务的高效执行。这些对话流程通常涉及多轮对话,每个对话都通过向 LLMs 发起 API 调用来实现。

图1展示了一些常见的基于 LLMs 的应用工作流程。这些流程不仅揭示了 LLMs 在不同场景下的应用模式,还体现了它们在处理复杂任务时的灵活性和高效性。以多代理编程应用为例,它展示了 LLMs 扮演的不同角色(如产品经理、架构师、工程师、QA 测试员)如何协作完成软件项目。在这个过程中,每个角色都通过调用 LLMs 来执行特定的任务,如设计 API、编写代码、进行代码审查等。这些任务之间的调用关系并非简单的线性流程,而是形成了一张复杂的调用关系图,即有向无环图(DAG)。这种结构不仅揭示了任务之间的依赖关系,也为优化整个工作流程提供了可能。
公共LLMs服务性能次优的主要表现
现在大多数 LLMs 应用都依赖于公共的语言模型服务,但这些公共 LLMs 服务提供商只能观察到大量的单独请求,而不了解任何应用级信息。例如,它们不清楚哪些请求属于同一应用,不同请求之间如何连接,或者是否存在任何相似性。这些丢失的应用级信息使得公共 LLMs 服务只能盲目地优化单个请求的性能,从而导致 LLMs 应用在端到端之间产生性能次优的问题。
目前的公共 LLMs 服务中存在三个关键问题:
网络延迟开销。在 API 的调度中,多个 LLMs 请求之间的依赖性和相互关联容易被忽略。这些 LLMs 请求只能在基于 LLMs 的应用客户端和公共的 LLMs 服务之间交互式执行。其中可能产生网络延迟、排队等额外开销,损害了 LLMs 应用端到端的性能。
调度目标错位。LLMs 请求可能存在不同的调度偏好。例如 Map Reduce 模式可以通过批次处理 Map 请求增加任务的吞吐量、减少端到端的延迟,在 Reduce 时则统一针对延迟问题进行优化。然而当前的公共 LLMs 服务难以区分这两种类型任务的差异,只会盲目地优化单个请求的延迟,这就导致了使用过程中的需求错位,不利于端到端的体验。
重复共性需求。LLMs 请求之间存在高度的共性。流行的 LLMs 应用会使用一个长系统提示,包括任务定义、示例和安全规则,来指导 LLMs 应用的行为。长系统提示通常是静态的,对所有用户都是通用的。但现有的公共 LLMs 服务是将每个请求单独对待,这些常见的前缀提示在每个请求中都被重复提供,导致存储、计算和内存带宽产生巨大的浪费。
总结来说,以上三类问题基本源于对 LLMs 请求相关性的理解不足。关键信息的缺失使得最新的优化技术难以在现在的服务中得到充分的应用。因此,开发一个能够将 LLMs 请求间的各种关系“传达”到服务后端的方法至关重要。
Parrot:引入语义变量优化性能
基于以上的分析,微软亚洲研究院的研究员们设计了 Parrot 工具,它可以通过简单的抽象语义变量保留大部分应用级信息,从而实现在增加系统复杂性和带来新信息进行优化之间的完美平衡。该论文已被计算机系统领域顶级学术会议 OSDI 2024 收录。
论文:Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
论文链接:https://arxiv.org/abs/2405.19888 (opens in new tab)
GitHub链接:https://github.com/microsoft/ParrotServe (opens in new tab)
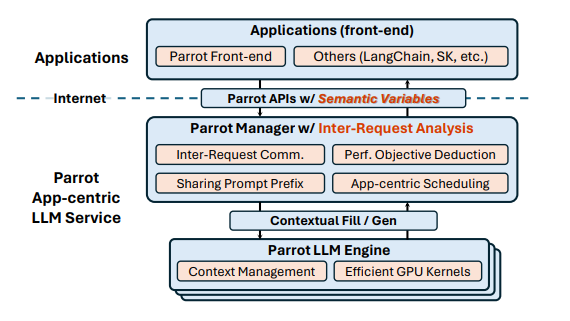
语义变量的引入
研究员们首先提出了语义变量(semantic variable)以实现对跨请求的抽象。图3是使用 Parrot 前端编写的一个简单的 LLMs 应用:编写一段 Python 代码并撰写测试代码。它包含三个语义变量:task、code 和 test,以及两个语义函数:WritePythonCode 和 WriteTestCode。
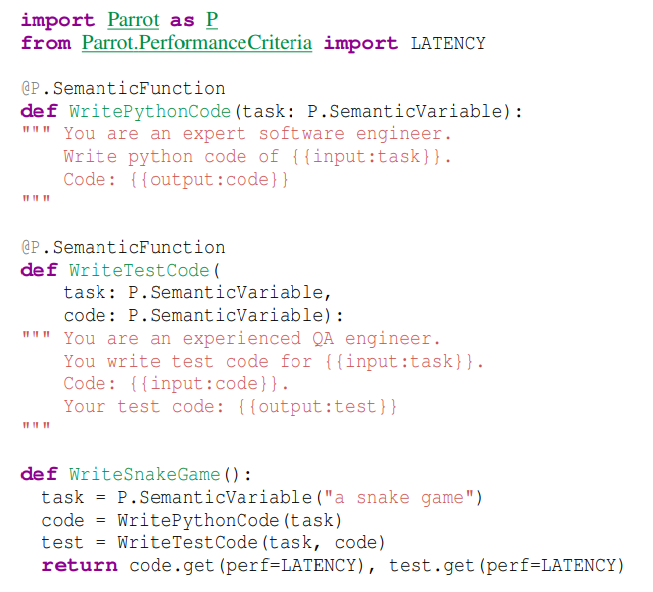
语义变量是一个字符串类型的变量,具有填充或未填充两种状态。研究员们在前端中将语义变量设计为 Python 中的变量。再基于 OpenAI 的 API 扩展,利用 Parrot 提供带有语义变量的 API,通过在提示中引入占位符,可以支持以 {{placeholder_name}} 这样的形式将每个占位符绑定一个语义变量,从而实现请求对语义变量的引用。
一个提示中的占位符和其绑定的语义变量可能有输入、输出两种关系:输入表示语义变量为这个占位符提供值;输出表示这个提示对应的请求为这个语义变量生成值。利用占位符和语义变量,Parrot 就能在服务端轻松建立 DAG。

此外,在提示中引入占位符的方式还能够使提示本身变得结构化(structural)。依赖语义变量,Parrot 首先可以构建出请求间的 DAG,再通过分析图上的信息来提取请求间关系的信息。其次,Parrot 能利用语义变量将提示分段,然后对每段分别进行哈希值计算等,以获取请求间在提示结构方面的关系。
综上,通过允许在提示中引入占位符,Parrot 扩展了现有的 API,引入了抽象的语义变量,实现了对请求间关系以及调度偏好的分析。
基于语义变量进行优化
在有了语义变量及其带来的请求间分析的原语后,研究员们丰富了系统获取应用端信息的能力,具体而言:
通过分析 DAG,Parrot 能找到互相依赖的请求(例如请求 A 的输出是请求 B 的输入)且可以将其改为异步的形式。用户可以通过带有语义变量的 API 将整个执行图先提交到系统中,再对最后输出的语义变量调用 “get” 来获取结果。之后,Parrot 会使用基于图的执行器对 DAG 图进行高效执行,并且在调度上会考虑请求与应用的关系从而最优化排队时间。这使得在 Parrot 中执行这样的相互依赖性请求时非常节省时间。
通过性能目标推导,Parrot 能实现端到端的优化(例如针对延迟、吞吐量)。Parrot 会给每个语义变量附带一个“性能目标”标记。用户可以提供整个 DAG 最后一个语义变量的性能目标,然后 Parrot 会在图上将这一标记“反向传播”,最后让每一个语义变量都拥有一个性能目标。此外,对于前面提到的 MapReduce 情况,Parrot 还会采用 Grouping 的策略,让调度器尽量将它们当作整体进行调度。
通过对提示结构的分析,Parrot 可以迅速找到不同请求间共享的相同前缀。Parrot 会使用类似 vLLM 的 fork 技术共享它们的 KV 缓存,并且在这一基础上支持更多情况:
- 动态生成的共享前缀。现有前缀共享技术大都需要提前知道所共享的前缀内容(具体值),但是在很多场景中,该内容是动态生成的。比如前述多代理编程应用中的代码段,其会被多个下游代理(如测试,代码审查等)所使用,由于它是动态生成的,所以现有共享前缀技术很难对其加速。对于 Parrot 系统而言,同一个 DAG 如果请求间共享相同的占位符(而非仅仅是静态字符串),即使其还没有真正具有值,Parrot 也可以将其判定出来并在运行时进行共享。
- 运行时加速。Parrot 设计了特殊的 CUDA kernel 与注意力算法,使得其在共享前缀的批量推理中不仅能够节省存储开销,还能够省掉不必要的数据加载和计算,从而能够达到很好的加速效果。
- 与其他优化的配合。需要注意的是,Parrot 的 Sharing Prefix 技术与其他系统中的部件是一体的,并不是独立的技术。例如配合 DAG,Parrot 具有 DAG 上的共享能力。总而言之,基于相同的抽象基础,Parrot 能够实现多种优化技术之间的协同工作。
通过一个综合性、启发性的算法,Parrot 能找到满足请求调度偏好的引擎,同时最小化负面影响。例如,对于相互依赖的请求,Parrot 会优先进行调度来减少排队时间;而对于带有特定性能目标标记的请求,Parrot 会根据不同的标记进行调度,以及将集群的请求当作一个整体进行调度。
潜力无限,推动LLMs应用性能提升
作为一个为 LLMs 应用提供的端到端 LLMs 服务,Parrot 展示了 LLMs 请求之间的依赖性和共性,使得一个新的优化空间成为可能。一方面 Parrot 聚焦于 LLMs 应用服务的优化,指出不应该把应用端请求都当成独立的请求来看待,而应该将其“传达”给服务端,并明确各请求间的关联;另一方面,Parrot 的技术细节,包括 API 设计、Engine API 都能为以后的 LLMs 应用服务设计提供参考。
Parrot 的评估结果表明,其可以通过高达11.7倍的优化改善基于 LLMs 的应用。它不仅能有效提高 LLMs 应用的效率,还能提升例如 LLMs 应用端到端性能的公平性等其他调度特性。未来,微软亚洲研究院的研究员们将持续探索该技术如何用于更广泛的 LLMs 应用场景,以及如何进一步优化 LLMs 应用的多维度性能。