

Entity linking is a cognitive capability essential to human communication. It contains two challenging components: first, entity conflation, where we recognize that even though an entity is referred to by different names, it is still one item; and second, entity disambiguation, where we differentiate between entities with the same name and distinguish them as separate. When you read scholarly articles, you invoke your entity linking capability when you realize that authors with the same name are different persons, or that different versions of a name, as well as acronyms, refer to the same entity – say, a conference.
As a research group working on artificial intelligence and on Microsoft Academic, we would like our system to possess and improve its entity linking capability so it can serve us better in discovering scholarship. This post explains how our group’s research on entity conflation and disambiguation works to make Microsoft Academic even more powerful for discovering scholarship.
So, where are conflation and disambiguation used in Microsoft Academic? Let’s start with real examples.
Take, for instance, an author who has published under two or more different names – let’s say, in some papers she used her middle initials, but in others, she did not. People who know her and her work would be able to tell, with varying degrees of confidence, that papers published by Mary A. Author and Mary Author are actually written by the same person. For machines, it is quite challenging to establish whether this is indeed the case. Similarly, we encounter many authors with identical, common names, such as John Smith, or Hao Chen. While many times it is difficult even for humans to differentiate among them, how can we teach the machine what papers belong to which Hao Chen? Should you be interested in learning more about the problem of entity linking in computer science, see publications on this topic on Microsoft Academic (opens in new tab)).
Traditionally, computer scientists have used classification or clustering algorithms to address conflation and disambiguation. However, these approaches are not able to use knowledge to differentiate among entities. As a research group working on artificial intelligence, we have taken an approach that combines two main sources of knowledge to solve this problem.
The first source of knowledge that we have been using for a while in Microsoft Academic is information about author affiliation, publication venues, and co-author network. We have all this knowledge neatly organized and easily accessible in the Microsoft Academic Knowledge Graph (opens in new tab) (which you can access via our API, or website (opens in new tab)). Our researchers have taught the machine to take these cues into consideration as it calculates the probability that entities are the same or different.
The second source of information we use is a recent development that we introduced last week. Our data scientists have developed a method for mining data from authors’ web sites and online CVs. Taking advantage of Microsoft’s web-scale infrastructure, by analyzing billions of documents found on the web, the team has taught the machine to recognize web pages that belong to researchers or may be CVs. Those pages have a set of common characteristics, a notable one being a list of publications. The list of publications found online is then compared with the data in the Microsoft Academic Knowledge Graph and used to inform the decision about whether authors with identical names are the same person or not.
Our approach is unique in scale. For identifying author homepages on the Web, we scan billions of documents from the Bing Index. We compare information from author homepages with information from more than 170 M papers in the Microsoft Academic Graph. In those 170 M papers, we see mentions of more than 600 M author names. By using the entity linking methods described here, we are able to conflate the number of authors from 500 to about 200 M.
Our approach is also unique in the use of artificial intelligence. In the methods we use to address the problem of entity linking, we train machines that scan billions of online documents to first recognize if a page is about academic publications or not. Second, for those pages that the machines recognize as academic, we teach computers to think like humans and decide whether they are author homepages or something else, such as conference proceedings. Third, we train machines to claim papers automatically for these authors. By recognizing paper titles in online documents and comparing them with the paper titles in the Microsoft Academic Graph, our algorithms are able to assign the papers to their correct author.
Using this innovative method that combines information from the Microsoft Academic Graph with information from web pages and online CVs, Microsoft Academic provides one of the best conflation/disambiguation experiences on the Web. For example, Microsoft Academic is able to distinguish between two authors with identical names, working at the same institution:
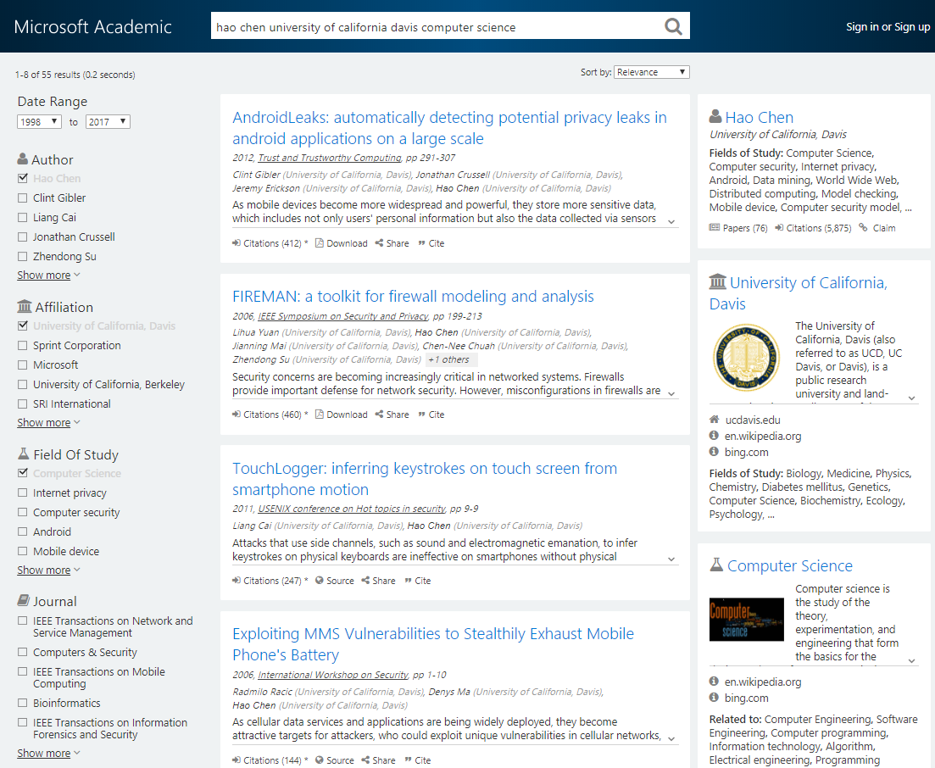
Hao Chen from University of California, Davis working in computer science (opens in new tab).
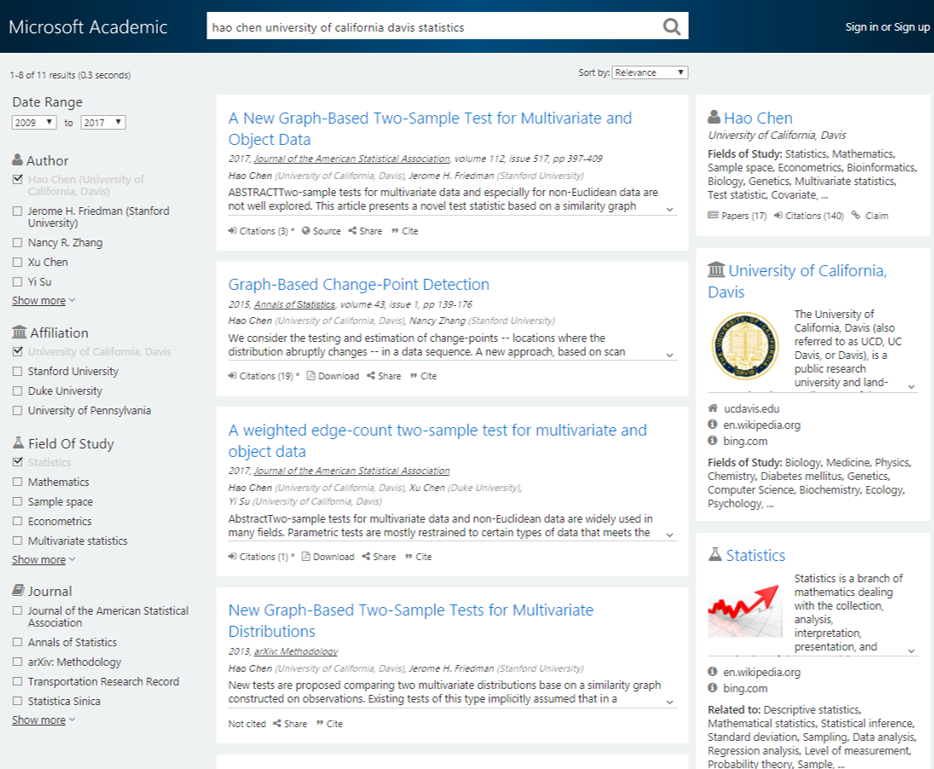
Hao Chen also from University of California, Davis, working in statistics (opens in new tab).
So, what does this mean for you?
All this means you can have confidence that when Microsoft Academic attributes a set of papers to an author, they were actually written by that person.
In fact, we at Microsoft Academic tend to be careful and rather conservative about attributing papers to authors. If the machine is not extremely confident that two authors with the same name are the same person, it will keep them as separate.In other words, we favor underconflation to overconflation. We made this choice in order to avoid situations where papers would be wrongly attributed to an author who did not write them. As a result, some authors will notice a similar pattern: most of their papers are under one author profile, with the occasional lone publication, which the machine understands to be somewhat different than the others, under a different profile with the same name.
There are many instances when even a human being would not be able to confidently state whether papers under the same name have been authored by one or more persons. In these cases, we depend on the authors themselves to tell us the truth. Authors can claim authorship and collect all the papers they wrote under one profile. If you have published research, and it shows up in Microsoft Academic under different author profiles, we encourage you to create an account and to claim all your papers under one name. You can do so by clicking the Claim button on the top right of the author profile page or paper page.
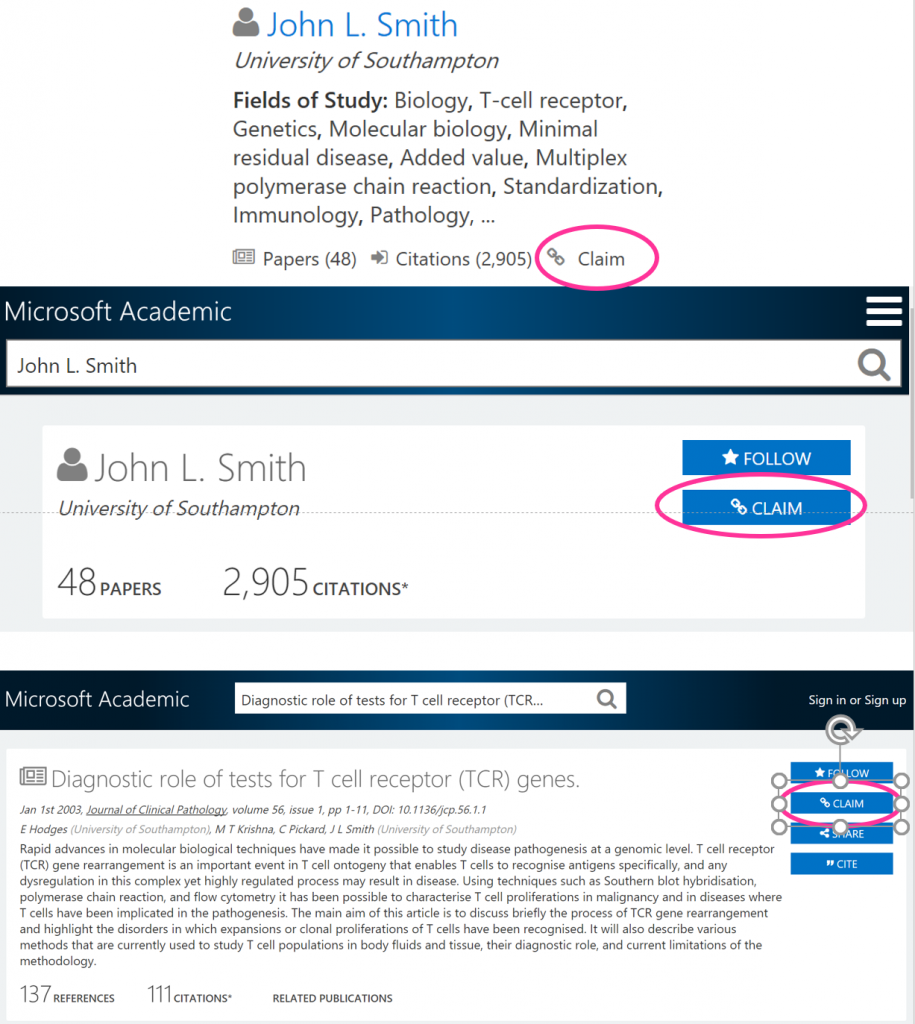
Claiming your papers ensures that you get correct attribution for your work, and that your publication and citation counts, as well as other information shown about you on the site, is in fact correct.
As our data science team says, “As our graph grows larger and richer, our system will become more intelligent and knowledgeable! And – Knowledge is power!” We are pleased to bring you powerful and knowledgeable semantic search, and we hope it helps you accomplish more in your knowledge seeking and discovery journey!
As always, we would like to hear from you either through the feedback link at the bottom right of the website, or on Twitter (opens in new tab). You can also find our project home page with this blog on the Microsoft Research site at aka.ms/msracad.
Happy researching!