

编者按:随着视频生成技术的飞速进步,我们见证了人工智能技术在视频清晰度、长视频连贯性以及对物理变化理解和镜头转换处理能力方面的显著提升。不过,这些高质量的生成结果是否完全符合我们的需求呢?显然,并非总是如此。由于生成模型的不可预测性,其生成结果常常与用户预期偏离。
在微软亚洲研究院的研究员们看来,创造性与可控性兼备的视频生成模型才是人工智能技术落地应用的关键。基于这一理念,研究员们研发了两项创新的视频生成技术——文生视频模型 MicroCinema 和视频编辑框架 CCEdit,旨在让视频生成更加贴合用户的切身需求。相关论文已被 CVPR 2024 接收。
在这个个性化表达的时代,每个人都是社交媒体内容的创作者。想象一下,拥有一套自己情有独钟的动物表情包——无论是快乐奔跑、好奇探头、悲伤低头,还是悠闲躺卧,每个动作都栩栩如生,同时还能适应各种场景,在古代与现代、虚拟与现实中自由穿梭——这将让你的社交互动更加生动、有趣,也更能展现自我。微软亚洲研究院的 MicroCinema 和 CCEdit 让这一创意想法成为了可能。
其中,MicroCinema 能够将根据文字描述生成的图片变为动态视频。例如,一只正在吃瓜看戏的松鼠:

当你对生成的视频有部分不满意,却又不希望重新生成不一样的视频时,CCEdit的视频编辑能力,可以进一步对动态视频进行个性化编辑。例如,更改背景:当松鼠吃的“大瓜”已经震惊银河系时:

当你感觉松鼠还不够威风凛凛时,可以给它披上吃瓜的盔甲:

或者,你希望它更可爱一点,那就调整主体,将松鼠变成二次元形象:

你也可以进行整体风格的转换,将松鼠置身于中国画中:

地球上动物种类在急剧减少。如果你想尽快制作一些珍惜动物的宣传短片,但却没有足够的时间亲自进行实地拍摄,那么 MicroCinema 和 CCEdit 也可以快速帮你完成这项工作。先让 MicroCinema 把根据文字描述生成的图片转化为动态视频。例如,一只高高兴兴弹着吉他的大熊猫:

再利用 CCEdit 进一步对动态视频进行个性化编辑,例如,更改背景,让这只熊猫走进梵高的世界中弹唱:

你还想制作一段金丝猴的视频,也可以直接在 CCEdit 中更改主体,将大熊猫修改为金丝猴:

或者,你希望制作一段中国画风格的视频片段,那么墨竹与黑白的大熊猫会更匹配:

为什么由文生视频模型 MicroCinema 和视频编辑框架 CCEdit 生成的视频,能够更精准地匹配文字描述,尤其在视频运动效果上满足用户的具体需求?关键在于它们的“可控性”。
微软亚洲研究院首席研究员罗翀表示:“尽管现有的生成技术极大地拓宽了创造的边界,但如果天马行空的创意不能准确地满足用户的实际需求,那么技术的潜力就无法被完全发挥出来并实现落地应用。理想的生成模型应当能够在精确理解用户指令和适应多变场景的基础上,根据用户的特定需求进行实时调整,确保创造力的可控性。”
MicroCinema:分而治之,实现视频按需生成
MicroCinema 之所以能够生成与文本描述高度匹配且流畅连贯的高质量视频,在于其采取了“分而治之”的策略。当前文生视频扩散模型(diffusion model)的主流方法是采用级联时空扩散模型,在文本-视频对之间进行学习,并通过在文本到图像生成模型中加入时间维度,再对文本和视频数据进行微调以创建文本到视频的模型。但是这种方法生成的视频常常会出现外观与时间不一致、不连贯的问题。
MicroCinema 通过将文本到视频的生成过程分为两个阶段来解决这一挑战:首先是文本到图像的生成,其次是图像加文本到视频的生成。在第一阶段,用户可以灵活利用先进的文本到图像模型(如 Stable Diffusion、Midjourney 和 DALL-E)来生成逼真且细节丰富的图像,这些图像作为视频的关键帧,为之后的视频片段生成提供了基础。在第二阶段,通过将这些生成的图像与初始文本一同作为输入,模型便可以减少对细节外观的关注,更专注于学习动态变化。
为了有效实施这一策略,研究员们引入了两项核心技术:利用外观注入网络(Appearance Injection Network)来增强保持给定图像外观的能力;通过外观噪声先验机制(Appearance Noise Prior)保持预训练的 2D 扩散模型的能力。
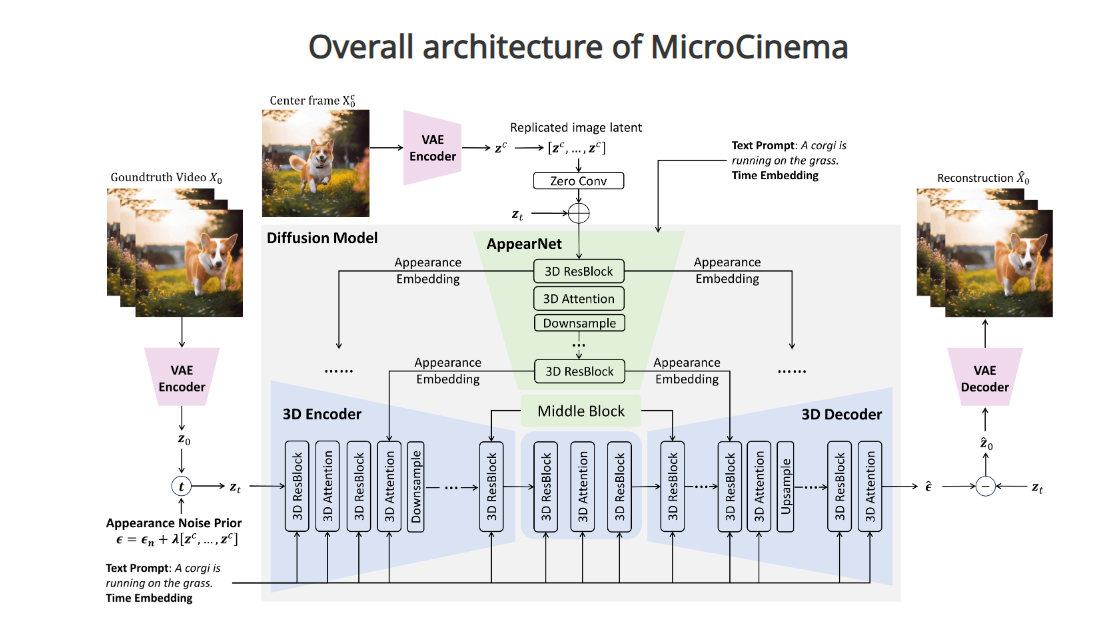
两段式的设计策略不仅使 MicroCinema 能够生成根据文本提示精确控制动作的高质量视频,而且显著降低了模型从头训练的成本。
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
论文链接:https://arxiv.org/abs/2311.18829 (opens in new tab)
GitHub 链接:https://wangyanhui666.github.io/MicroCinema.github.io/ (opens in new tab)
以下两个示例展示了 MicroCinema 是如何精确捕捉和再现文本描述:

一辆黄色的车在类似梵高画作风格的现代城市夜景中行驶

耀眼的阳光下,行走在金色麦田中的巨型恐龙骨架
CCEdit:三叉戟网络,让视频编辑更可控
尽管现有视频生成模型拥有强大的创造力,但其生成的视频结果并不是总能精确符合用户的编辑意图或艺术构想,特别是无法对结果进行二次编辑。CCEdit 通过其创新的三叉戟网络结构,有效分离结构控制和外观控制,为用户提供了一系列广泛的编辑功能,包括前景替换、背景修改、风格转换和特效添加等。
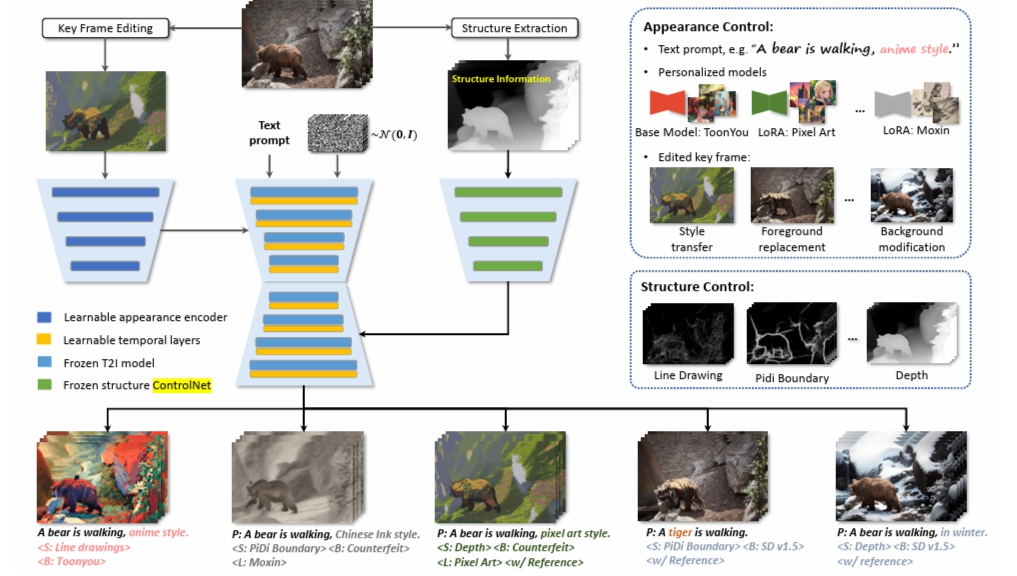
CCEdit 网络由三个关键组件构成:负责文本到视频生成的主分支,以及两个专门用于结构和外观控制的辅助分支。
主分支利用预训练的文本到图像扩散模型,通过插入时间序列层将其转换为文本到视频模型。除了使用文本提示进行外观图像控制,CCEdit 还允许用户调用 Stable Diffusion 社区的个性化文本到图像模型(如 ToonYou、LoRA、Rev Animated)来增强内容的创造性与灵活性。结构分支采用多样的 ControlNet 架构,从输入视频中提取每帧的结构信息和动作轨迹,以实现无缝的结构继承和不同粒度上的结构控制。外观分支则会把通过特征提取处理编辑后的关键帧信息,有效地融入到主分支,支持将用户自己设计的图像作为关键帧,进行细粒度的外观调整。而所有这些控制选项都是在同一框架内无缝集成的。
CCEdit 网络的设计策略为用户提供了广泛的控制权,使视频生成不仅拥有无限的创造潜力,同时也具备高度的可控性,满足了用户从细节到整体的个性化编辑需求。
CCEdit: Creative and Controllable Video Editing via Diffusion Models
论文链接:https://arxiv.org/abs/2309.16496 (opens in new tab)
GitHub 链接:https://ruoyufeng.github.io/CCEdit.github.io/ (opens in new tab)
以下是使用 CCEdit 进行视频编辑的几个示例,展现了其在不同场景下的应用能力:

全局修改,将一个年轻女孩对着镜头微笑的场景转变成漫画风格

全局修改,将城市夜景转化为赛博朋克风格

前景编辑,把一只行走的老虎转换成2D动画风格

背景编辑,把一名女性在春日的田野里享受美酒的背景改为绿色的田野

综合编辑,将一只可爱的狗狗变成一条霸气的喷火龙,背景是雷雨交加的悬崖顶

通过控制结构生成不同样式的视频,比如线稿图、PiDi 边界图、草图、深度图等

通过插入关键帧,将视频修改为自定义风格
多轮互动修改将是未来视频生成模型必不可少的功能
在这个技术革新的时代,文生视频模型凭借其独有的创造力和强大的性能,“创作”出了许多令人瞩目的作品,同时也引发了大众的广泛关注。然而,在对技术进行前沿探索的同时,微软亚洲研究院智能多媒体组的研究员们深入思考了一个关键问题:如果无法对生成结果进行按需求的精确编辑和调整,那么这些先进工具在日常生活中的实际应用价值又有多大?
正是基于这样的思考,研究员们在开发 MicroCinema 和 CCEdit 的过程中,特别强调了“可控性”这一核心原则。这不仅体现了对技术性能的追求,也反映了他们对人工智能技术未来发展方向的期待。“未来,视频编辑和生成技术将不仅限于单次指令的响应。相反,它们需要能够通过多轮对话与用户进行互动,准确地理解并实施用户的具体需求,从而逐步精细化并满足用户的个性化编辑意图,创造出更加匹配需求的内容。”罗翀说。
MicroCinema 和 CCEdit 的开发标志着研究员们在可控视频生成技术领域的初步探索。未来,研究员们将继续沿着这一思路,进一步推动人工智能视频生成技术的发展,使其更贴近用户的实际需求和创意愿景。