

By Jifeng Dai and Steve Lin, Microsoft Research Asia
Over the decades that we’ve spent as researchers and technical leaders in computer vision, there have been few developments as astounding as the rapid progress in image recognition. In the past several years, we have seen object detection performance skyrocket from approximately 30 percent in mean average precision to more than 90 percent today, on the PASCAL VOC benchmark. For image classification on the challenging ImageNet dataset, state-of-the-art algorithms now exceed human performance. These improvements in image understanding have begun to impact a wide range of high-value applications, including video surveillance, autonomous driving, and intelligent healthcare.
The driving force behind the recent advances in image recognition is deep learning, whose success is powered by the formation of large-scale datasets, the development of powerful models, and the availability of vast computational resources. For a variety of image recognition tasks, carefully designed deep neural networks have greatly surpassed previous methods that were based on hand-crafted image features. Yet despite the great success of deep learning in image recognition so far, there are numerous challenges that remain to be overcome before it can be employed for broader use.
Improving model generalization
One of these challenges is in how to train models that generalize well to real-world settings that have not been seen in training. In current practice, a model is trained and evaluated on a dataset that is randomly split into training and test sets. The test set thus has the same data distribution as the training set, as they both are sampled from the same range of scene content and imaging conditions that exist in this data. However, in real-world applications, the test images may come from data distributions different from those used in training. For example, the unseen data may differ in viewing angles, object scales, scene configurations, and camera properties. A recent study shows that such a gap in data distribution can lead to significant drops in accuracy over a wide variety of deep network architectures [1]. The susceptibility of current models to natural variations in the data distribution can be a severe drawback in critical applications such as autonomous vehicle navigation.
Exploiting small and ultra-large-scale data
Another existing challenge is how to better exploit small-scale training data. While deep learning has shown great success in various tasks with a large amount of labeled data, current techniques generally break down if few labeled examples are available. This condition is often referred to as few-shot learning and it demands careful consideration in practical applications. For example, a household robot is expected to recognize a new object after being shown it just once. A human can naturally do so even if the object is manipulated, such as folding up a blanket. How to endow deep learning networks with such generalization ability is an open problem in research.
At the other extreme is how the performance of recognition algorithms can be effectively scaled with ultra-large-scale data. For critical applications such as autonomous driving, the cost of recognition errors is very high. So enormous datasets, containing hundreds of millions of images with rich annotations, are built with hopes that the accuracy of the trained models can be dramatically improved. However, a recent study suggests that current algorithms cannot necessarily exploit such ultra-large-scale data as effectively [2]. On the JFT dataset containing 300 million annotated images, the performance of a variety of deep networks increases just logarithmically with respect to the amount of training data (Image 1). The diminishing benefits of greater training data at large scales present a significant issue to address.
![Image 1 The left graph uses the mAP @ [0.5, 0.95] metric on the COCO minival test set, and the right graph uses the mAP @ 0.5 metric on the PASCAL VOC 2007 test set.](https://www.microsoft.com/en-us/research/uploads/prod/2018/10/image1.png)
Image 1 The left graph uses the mAP @ [0.5, 0.95] metric on the COCO minival test set, and the right graph uses the mAP @ 0.5 metric on the PASCAL VOC 2007 test set.
Comprehensive scene understanding
In addition to problems related to training data and generalization, an important topic for investigation is comprehensive scene understanding. Besides recognizing and locating objects in a scene, humans also infer object-to-object relations, part-to-whole object hierarchies, object attributes, and 3D scene layout. Acquiring a broader understanding of scenes would facilitate applications such as robotic interaction, which often requires knowledge beyond object identity and location. This task not only involves perception of the scene, but also necessitates a cognitive understanding of the physical world. There remains a long way to go in reaching this goal (Image 2).
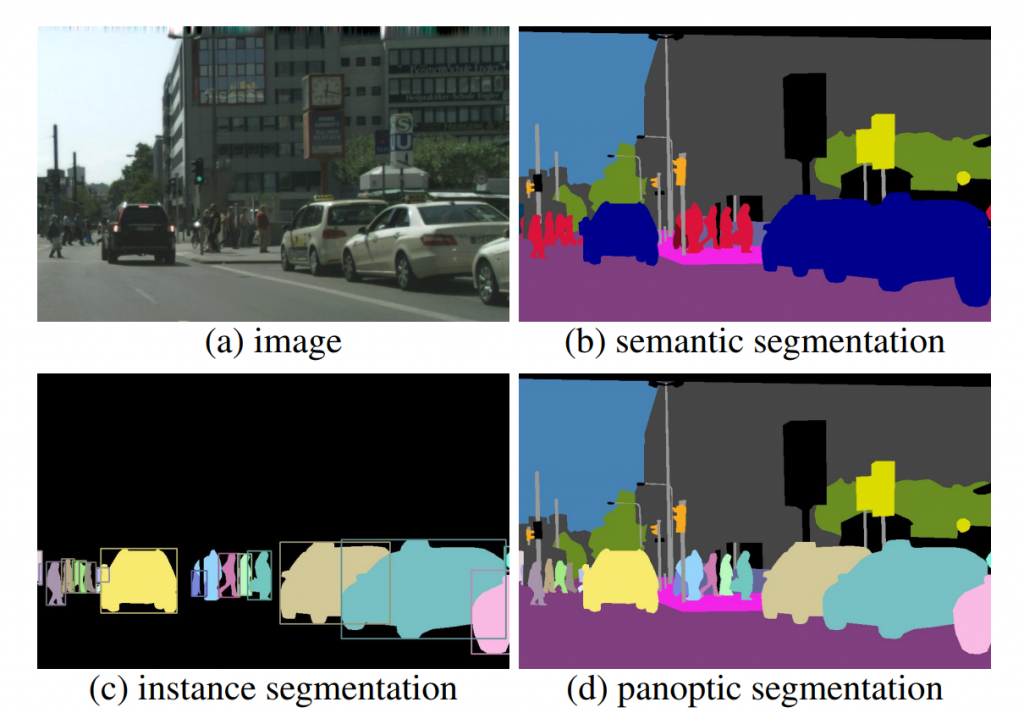
Image 2 An image needs to be understood at several levels.
Automating network engineering
A final challenge that we wish to mention is the need to automate network engineering. In recent years, the field has seen its focus shift from the crafting of better features to designing new network architectures. However, architecture engineering is a tedious process that deals with numerous hyperparameters and design choices. Tuning these elements requires a tremendous amount of time and effort by experienced engineers. What’s more, the optimal architecture for one task may well be quite different for another task. Although investigations into automatic neural architecture search have begun, they are still at an early stage and have been limited only to image classification. The search space of current approaches is rather narrow, as they seek a locally optimal combination of existing network modules (e.g., depth-wise convolutions and identity connections) and are unable to discover new modules (Image 3). Whether these current approaches are adequate for more sophisticated tasks is unclear.
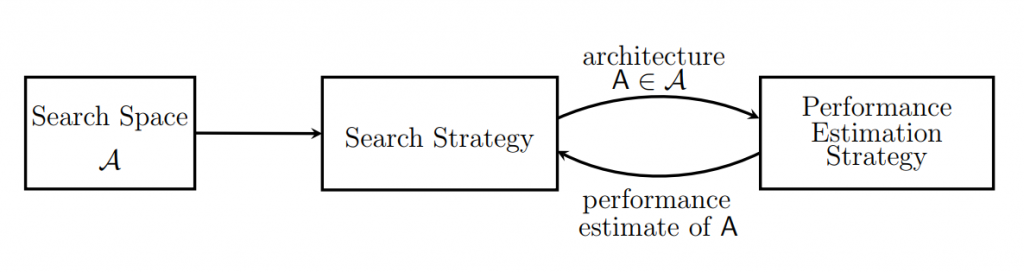
Image 3 Abstract diagram of the neural structure search algorithm.
Despite these challenges, we still believe in the huge potential of deep learning for image recognition. Opportunities abound for addressing these issues and rapidly pushing the field forward. Several of these directions are described below.
Integrating common sense
One important direction is to integrate common sense into deep learning. At present, deep learning is predominantly used as a purely data-driven technique, where the network fits a non-linear function to annotated samples given in the training set, and then applies the learned function to image pixels at test time. No knowledge outside of the training set is used. By contrast, humans conduct recognition not only based on samples they have seen before, but also based on their common-sense knowledge about the real world. People are able to reason about what they see to avoid illogical recognition results. Moreover, when they encounter something new or outside of their expectations, humans can quickly adapt their knowledge to account for this new experience. The challenge lies in how to acquire, represent, and reason with common knowledge within deep networks.
Reasoning geometrically
Another promising direction is to jointly perform image recognition and geometric reasoning. In the leading models for image recognition, only 2D appearance information is considered. By contrast, humans perceive 3D scene layouts together with inferring the semantic categories that exist within. A 3D layout may be derived not only from binocular vision, but also from geometric reasoning on 2D input, such as when people look at photos. Joint image recognition and geometry reasoning offers mutual benefits. The 3D layout determined from geometric reasoning can help to guide recognition in instances of unseen perspectives, deformations, and appearance. It can also eliminate unreasonable semantic layouts and help in recognizing categories defined by their 3D shape or functions. For example, there exist large intra-class appearance variation among sofas. However, they share common properties that can aid in identifying them, such as having a horizontal surface for sitting and a back surface for support. On the other hand, recognized semantics can regularize the solution space of geometric reasoning. For example, if a dog is recognized in a scene, its corresponding 3D configuration should fit the 3D shape model of dogs.
Modeling relationships
Relational modeling also holds great potential. To comprehensively understand a scene, it is vital to model the relationships and interactions among the object entities that are present (Images 4 and 5). Consider two images that each contain a person and a horse. If one displays the person riding the horse and the other exhibits the horse trampling the person, what is shown in these images has an entirely different meaning. Moreover, the underlying scene structure extracted through relational modeling can help to compensate when current deep learning methods falter due to limited data. Though efforts are already underway for this problem, the research is still preliminary and there is much room for exploration.

Image 4 Reconstruct the point clouds of complex dynamic scenes from two different frames of video.
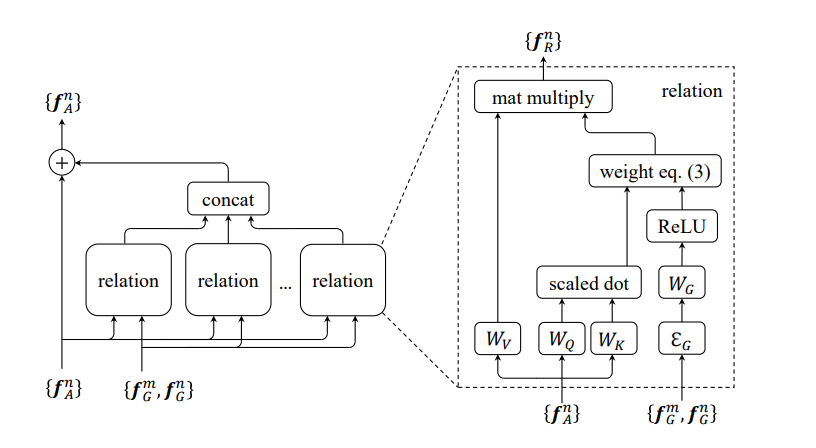
Image 5 Relational network in target detection. f_A represents the external features of objects, and f_G represents the geometric characteristics of objects.
Learning to learn
An additional direction to mention is meta learning, which aims to learn the learning process. This topic has attracted considerable attention recently and neural architecture search can be deemed as one application of meta learning. The research on meta learning, however, is still at an early stage, as the mechanisms, representations, and algorithms for modeling the learning process are currently rudimentary. Taking neural architecture search as an example, it is restricted to simple combinations of existing network modules only. The meta learner cannot capture the subtle intuition and sharp insight needed to create novel network modules. With advances in meta learning, the full potential of automatic architecture design may be unleashed, leading to network configurations that surpass those obtained through manual engineering (Image 6).
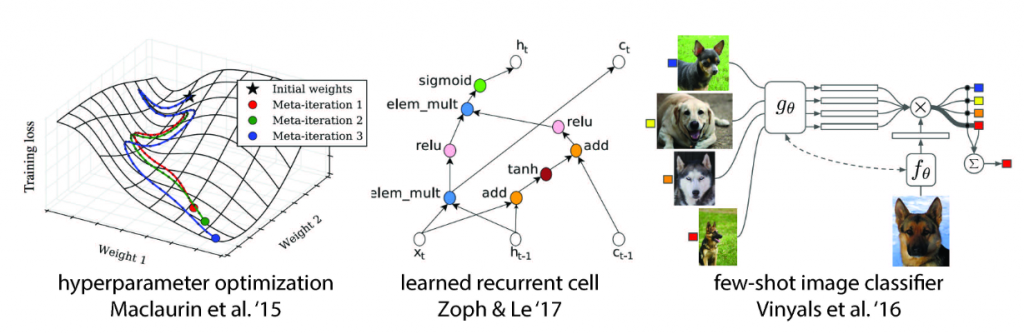
Image 6 Recent progress in meta learning. From left to right, they are meta parametric optimization, neural structure search, and small sample image classification respectively.
It is an exciting time to be working on image recognition, a time full of opportunities for driving the field forward and impacting futuristic applications. We eagerly anticipate the advances soon to come and expect these new technologies to transform our lives in profound and amazing ways.
[1] Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, Vaishaal Shankar. Do CIFAR-10 Classifiers Generalize to CIFAR-10? arXiv preprint, 2018.
[2] Chen Sun, Abhinav Shrivastava, Saurabh Singh, Abhinav Gupta. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. ICCV, 2017.