

Authors:
Tommy Guy and Kidus Asfaw
We noticed an odd case of nondeterminism in Spark’s randomSplit function, which is often used to generate test/train data splits for Machine Learning training scripts. There are other posts, notably this one (opens in new tab) that diagnose the problem, but there are a few details to spell out. We also want to suggest an alternative to randomSplit that will guarantee determinism.
The Problem
If you want to split a data set 80/20 in Spark, you call df.randomSplit([0.80, 0.20], seed) where seed is some integer used to reseed the random number generator. Reseeding a generator is a common way to force determinism. But in this case, it doesn’t work! In some cases (we’ll identify exactly which cases below), randomSplit will:
- Leave some rows out of either split
- Duplicate other rows into both splits
- On two separate runs on the same data with the same seed, assign data differently.
This feels like a bit of a bait and switch. I feel like any function that accepts a seed is advertising that it should be deterministic: otherwise why bother with the seed at all?
Luckily, there is a way to force randomSplit to be deterministic, and it’s listed in several (opens in new tab) places (opens in new tab) online (opens in new tab). The trick is to cache the dataframe before invoking randomSplit. This seems straightforward, but it relies on a solid understanding of Spark internals to gain an intuition on when you should be careful. Ultimately, Spark tries hard to force determinism (and more recent Spark versions are even better at this) but they can’t provide 100% assurance that randomSplit will work deterministically. Below, I’m going to suggest a different way to randomly partition that will be deterministic no matter what.
Pseudorandomization: A Reminder
Just as a quick reminder, the way computers produce “random” numbers is actually pseudorandom: they start with some number then iterate in a complicated but deterministic way to produce a stream of numbers that are uncorrelated with each other. In the example below, we assign random numbers to some names, and we show that we can do this repeatably

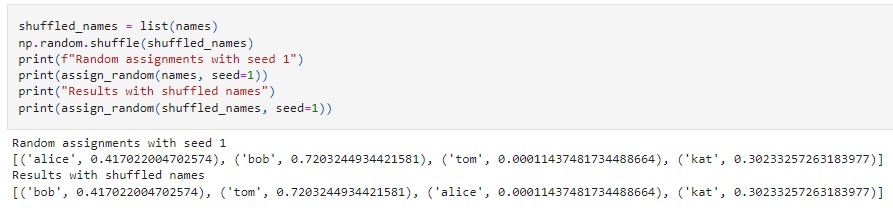
So, the way to make a deterministic algorithm with a random number generator is to:
- Set the seed the same way.
- Invoke the random number generator the exact same number or times and use the sequence in the exact same way.
Another Reminder: Spark DataFrame definition vs execution
Spark makes a distinction between defining what to do and executing the defined compute. Some expressions on DataFrames are transformations that convert one DataFrame to a new DataFrame while others are actions that execute a sequence of transformations. There are many sources talking about this distinction online, but the original paper (opens in new tab) on Spark is still a really great intro. (Aside: the paper talks about Resilient Distributed Datasets, which are a foundational element that DataFrames use).
If you’ve worked in Spark long at all, you’ve seen this phenomenon. I can execute the following commands in a REPL and they succeed almost immediately no matter how big the data really is:
df = spark.read.parquet(“/some/parquet/file/pattern*.parquet”)
df = df.filter(df[‘amount’] > 4000).filter(df[‘month’] != ‘jan’).show()
df2 = spark.read.parquet(“/someother/parquet/file/pattern*.parquet”)
df3 = df.join(df2)
That’s because all I’ve done so far is define a set of computations. You can see the plan by trying
df3.explain()
But when we execute something like df3.count(), we issue an action. The set of transformations that create df3 execute on Spark workers, and it can take much longer to execute the statement because it blocks on the actual Spark action finishing.
In a normal python script, if you trace the program on a white board, you can basically track the system state line by line. But in a pyspark script, it’s much harder to trace when the “real” work (the actions) take place, or even when and how often they take place.
randomSplit([0.8, 0.2], seed) creates two DataFrames, and each results in an action
Ok, so now it’s time to look at the randomSplit function. The actual code (opens in new tab) is below:

This is what it does:
- Sort the data within each partition. This ensures that within a Spark partition, the random number generator in Sample will execute the same number of times and will use the random numbers in the same exact way.
- Normalize the weights.
- Issue a series of calls to Sample with different sliding windows and with the same seed. Those calls are totally independent, and each call returns a Dataframe.
- Return a list of DataFrames: one per sample partition.
Sample is a transformation: it adds to the DAG of transformations but doesn’t result in an action. In our example of an 80/20 split, the first call to Sample will use a random generator to assign a value between 0 and 1 to every row, and it will keep rows where the random value is <0.8. The second call will assign new random values to every row and keep rows where the random value is >0.8. This works if and only if the random reassignment is exactly the same in both calls to Sample.
Each of the 2 DataFrames (one with 80% of data and one with 20%) corresponds to a set of transformations. They share the set of steps up to the sample transformation, but those shared steps will execute independently for each random split. This could extend all the way back to data reading, so data would literally be read from disk independently for the 80% sample and the 20% sample. Any other work that happens in the DataFrame before Sample will also run twice.
This all works just fine assuming every step in the upstream DAG deterministically maps data to partitions! If everything is deterministic upstream, then all data maps to the same partition every time the script runs, and that data is sorted the same way in randomSplit every time, and the random numbers generated use the same seed and used on the same data row every time. But if something upstream changes the mapping of data to partitions then some rows will end up on different partitions in the execution for the 80% sample than they end up in the 20% sample. To summarize:
- If a non-deterministic process maps data to partitions, then the non-deterministic process could run independently per partition.
- If the independent, non-deterministic transformation changes something that Spark uses to partition data, then some rows may map to partitions differently in each DAG execution.
- That data is assigned different random numbers in the 80% sample and 20% sample because the random numbers in Sample are used differently in the two samples. In fact, likely nearly all data gets different random numbers because any change to partitioning impacts data that is sorted.
What could cause the DataFrame input to randomSplit to be non-deterministic? Here are a few samples:
- Changing data. If your data changes between reads, the two frames could start with different data. This could happen if you are, say, reading from a stream with frequent appends. The extra rows from the second action would end up somewhere.
- Some UDFs (User Defined Functions) can be nondeterministic. A classic example would be a function that generates a UUID for every row, especially if you later use that field as a primary key.
There used to be a much more nefarious problem in Shuffle (opens in new tab) when used in df.partition(int). Spark did a round robin partitioning, which meant rows were distributed across partitions in a way that depended on the order of data in the original partition. By now, you should see a problem with that approach! In fact, someone filed a bug (opens in new tab) pointing out the same sort of nondeterministic behavior we saw in randomSplit, and it was fixed. The source (opens in new tab) for round robin shuffling now explicitly sorts to ensure rows are handled in a deterministic order.
A Few Workarounds
There are really two options, and they are documented elsewhere (opens in new tab) in more detail. They boil down to:
- Force the upstream DAG to only run once. This is what cache does: it persists the DataFrame to memory or disk. Subsequent reads hit the cache, so
someNonDeterministicDataFrame.cache().randomSplitforces the DAG creatingsomeNonDeterministicDataFrameto run once, saves results in cache, then forces all samples in randomSplit to read from the cache. The cache is deterministic by definition: it’s a fixed data set. - Do something that deterministically forces data to partitions. Do this after the nondeterministic transformation, and be careful not to partition on something that is nondeterministic (like a guid you build in a UDF)!
Both workaround options require that you think globally to act locally. That breaks the encapsulation that is at the core of software engineering! You are left to either understand every step upstream in the DAG (likely by using explain function) and hoping that doesn’t change or adding potentially expensive extra computation to guard against changes. Both of these options effectively require global knowledge and global change knowledge! For example, my team at Microsoft intentionally separates the problem of reading data from disk and producing DataFrames from the actual Machine Learning training and inference steps. We don’t want you to think globally!
An Alternative Fix: Deterministic by Design Shuffle
randomSplit relies on DataFrame structure to produce deterministic results: consistent data-to-partition mapping and consistent ordering within partition (enforced in the method). Another approach is to deterministically use the data values to map to partitions. This is an approach that is commonly used in AB test initialization (I described it here (opens in new tab)) that has a few interesting properties:
- The same input always maps to the same sample.
- You can use a subset of columns to consistently hash all data that matches on the subset to same sample. For instance, you could map all data from a userId to the same random split.
- The algorithm is stateless: this is important for scale in AB testing but for our purposes it makes implementation easier.
The basic idea for a row is:
- Concatenate any columns you want to sample on into a new column.
- Add a salt to the new column (we’ll use seed), which allows us to produce different partitions at different times.
- Hash the column.
- Compute the modulus of the hash using some large modulus number (say 1000) [0]
- Pick a set of modulus outputs for each split. For an 80/20 split, moduli 0-799 is the 80% split and 800-999 is the 20% split.
In pyspark:
