

Federated learning is a new collaborative learning method that involves multiple decentralized edge devices to build a privacy-preserving shared data model without exchanging locally bound data. This technique is critical to many real-world scenarios where privacy is an issue, such as when personal data is stored on mobile devices or when patient records in hospital networks cannot be shared with central servers.
Unsupervised learning is becoming essential in federated systems because data labels are typically scarce in practical scenarios. The fact that clients must rely on locally defined pretext tasks without ground-truth labels also adds to the complexity of the problem. For this problem, Zhang et al. proposed FedCA, a model that uses local data features and external datasets to reduce representation inconsistency [1]. Wu et al. proposed FCL that exchanges encrypted local data features for privacy and employs a neighborhood matching approach to manage decentralized client data [2]. However, these methods raise new privacy concerns because of explicit data sharing.
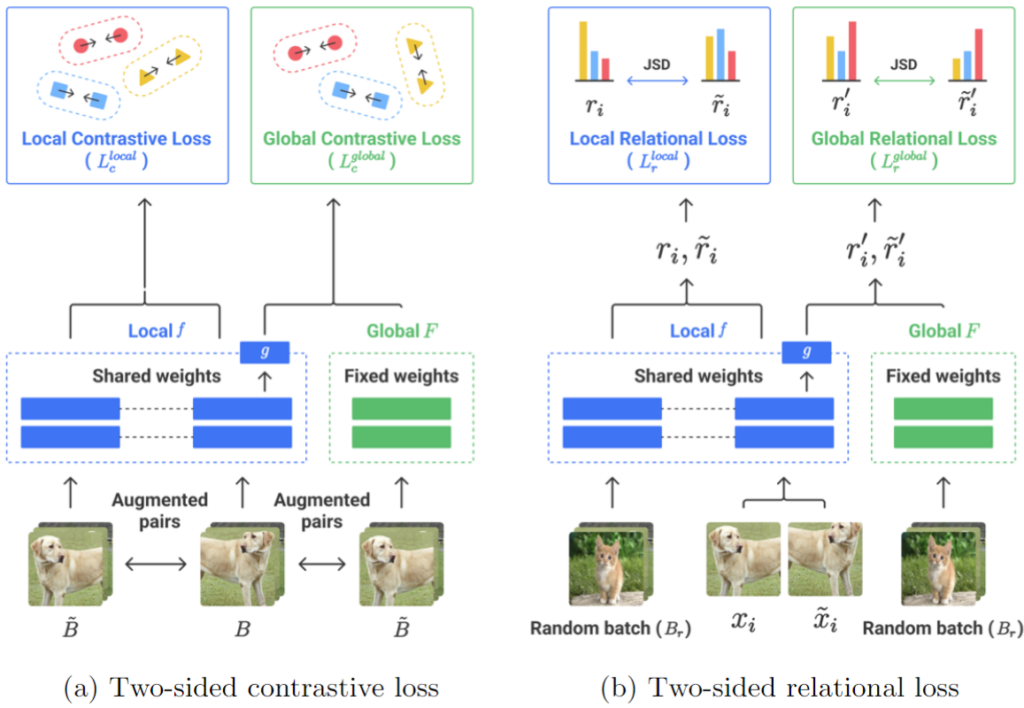
Researchers from the Institute for Basic Science and the KAIST School of Computing (Meeyoung Cha, Sundong Kim, Sungwon Han, and Sungwon Park) collaborated with researchers from Microsoft Research Asia’s Social Computing Group (Xing Xie, Fangzhao Wu, and Chuhan Wu) to propose FedX, a new advance in unsupervised federated learning that learns semantic representation from local data and refines the central server’s knowledge through knowledge distillation. Figure 1 depicts its main design components: contrastive loss and relational loss. FedX extends the FedAvg [3] baseline model’s local updating processes in each client by redesigning loss objectives and distilling knowledge locally (i.e., local knowledge distillation) and globally (i.e., global knowledge distillation).
Local knowledge distillation maximizes the embedding similarity between two views of the same data instance, while minimizing that of other instances (i.e., local contrastive loss). The design of soft labeling further reduces the contrastive loss by introducing similarities between an anchor and randomly selected instances called relationship vectors [4]. Researchers minimized the distance between two different relationship vectors to transfer structural knowledge and achieve fast training speed (i.e., local relational loss). Global knowledge distillation uses the global model’s sample representation as an alternative view near the local model’s embedding. Concurrent optimization teaches the model semantics while regularizing data bias. These goals require no extra communication or computation.


The experiments conducted by researchers confirm the need for both local and global knowledge distillation. It is also demonstrated that FedX can be used to improve existing algorithms (see Figure 2). FedX-enhanced models reported a lower angle difference between the local and global embeddings (see Figure 3-a), indicating that the local model can distill the refined knowledge of the global model. FedX-enhanced models also have larger inter-class angles, demonstrating better class discrimination (see Figure 3-b). The paper «FedX: Unsupervised Federated Learning with Cross Knowledge Distillation» will be presented at the 2022 European Conference on Computer Vision (ECCV).
Paper link: https://arxiv.org/abs/2207.09158 (opens in new tab)
[1] Zhang, Fengda, et al. “Federated unsupervised representation learning.”, ArXiv Preprint, 2020.
[2] Wu, Yawen, et al. “Federated Contrastive Representation Learning with Feature Fusion and Neighborhood Matching.”, OpenReview, 2021.
[3] McMahan, Brendan, et al. “Communication-efficient learning of deep networks from decentralized data.” Artificial intelligence and statistics, 2017.
[4] Tejankar, A, et al. “ISD: Self-supervised learning by iterative similarity distillation.”, ICCV, 2021
[5] Chen, T, et al. “A simple framework for contrastive learning of visual representations”, ICML, 2020.
[6] Grill, Jean-Bastien, et al. “Bootstrap your own latent-a new approach to self-supervised learning.”, NeurIPS, 2020.