

Error correction is an important post-processing method in speech recognition that aims to detect and correct errors in speech recognition results, thereby further improving the accuracy of speech recognition. Many error correction models use autoregressive models with high latency, but speech recognition services have strict requirements on the latency of the models. In real-time speech recognition scenarios, autoregressive error correction models cannot be used for online deployment.
In order to speed up the error correction model in speech recognition, researchers at Microsoft Research Asia and Microsoft Azure Speech proposed FastCorrect, a non-autoregressive error correction model based on Edit Alignment that can speed up the autoregressive model by six to nine times while maintaining comparable error correction ability. Because speech recognition models can often deliver multiple alternative recognition results, the researchers further proposed FastCorrect 2, where the multiple results are used to confirm each other and improve performance. The research papers on FastCorrect 1 and 2 had been accepted by NeurIPS 2021 and EMNLP 2021 respectively.
FastCorrect
Edit alignment
FastCorrect leverages non-autoregressive generation with edit alignment to speed up the inference of the autoregressive correction model. In FastCorrect, researchers first calculate the edit distance between the recognized text (source sentence) and the ground-truth text (target sentence). Since the source and target tokens are aligned monotonically in Automatic Speech Recognition (ASR) (unlike shuffle error in neural machine translation), by analyzing the insertion, deletion and substitution operations in the edit distance, the number of target tokens that correspond to each source token after editing (i.e., 0 means deletion, 1 means unchanged or substitution, and ≥2 means insertion) could be obtained, as shown in Figure 1. In some cases, there would be several possible alignments of a source-target sentence pair, and the final alignment based on the path match score (the number of matched tokens in alignment) and frequency score (reflecting confidence of alignment in the language model) would be chosen.

Model architecture
FastCorrect adopts a non-autoregressive encoder-decoder structure with a length predictor to bridge the length mismatch between the encoder (source sentence) and decoder (target sentence). As shown in Figure 2, the encoder takes the source sentence as input and outputs a hidden sequence that is: 1) fed into a length predictor to predict the number of target tokens corresponding to each source token (i.e., the edit alignment obtained in the previous subsection), and 2) used by the decoder through encoder-decoder attention. The label of the length predictor is obtained from edit alignment, and the detailed architecture of the length predictor is shown in the right sub-figure of Figure 2.

Experimental results
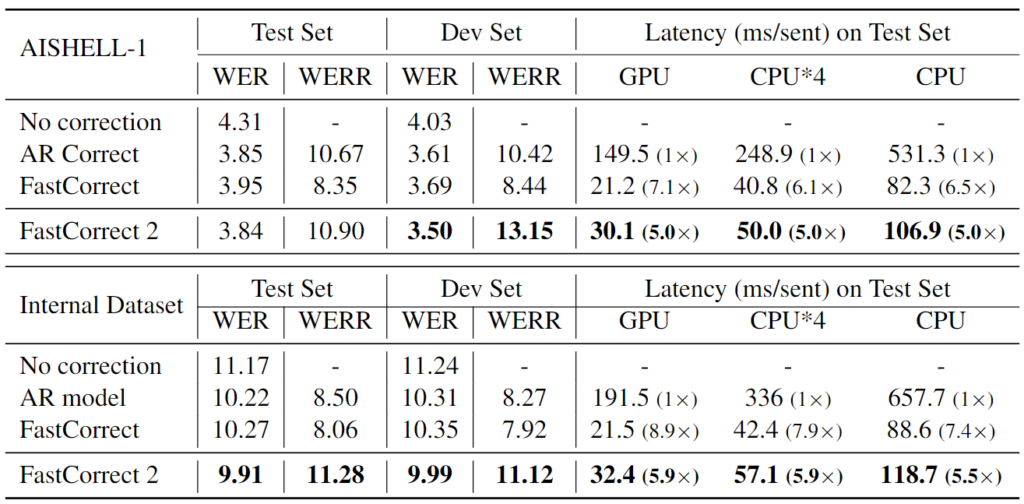
Researchers reported the accuracy and latency of different error correction models on AISHELL-1 and on an internal dataset, as shown in Table 1. We made several observations: 1) The autoregressive (AR) correction model can reduce the word error rate (WER) (measured by word error rate reduction (WERR)) of the ASR model by 15.53% and 8.50% respectively on the AISHELL-1 test set and the internal dataset. 2) LevT, a typical non-autoregressive model from NMT, achieves minor WERR on AISHELL-1 and even leads to WER increase on the internal dataset. Meanwhile, LevT can only speed up the inference of the AR model by two to three times on GPU/CPU. 3) FELIX only achieves 4.14% WERR on AISHELL-1 and 0.27% WERR on the internal dataset, which is significantly worse than FastCorrect, although the inference speedup is similar. 4) FastCorrect model speeds up the inference of the AR model by six to nine times on the two datasets on GPU/CPU and achieves 8-14% WERR, nearly comparable with the AR correction model in accuracy.

FastCorrect 2
The key challenge in ASR error correction is to detect and correct the error tokens. Because beam search is commonly used in ASR, multiple candidates are usually generated and available for error correction. We argue that multiple candidates can carry out the voting effect, which means that tokens from multiple sentences can conduct verification with each other.
For example, if the beam search candidates are the three sentences “I have cat,” “I have hat,” and “I have bat,” then the first two tokens of the three sentences are likely to be correct since they are the same among all beam candidates. The inconsistency on the last token shows that: 1) this token may need correction, and 2) the pronunciation of the ground-truth token may end with “æt”. The voting effect can be utilized to boost ASR correction by helping the model detect the error token and giving clues about the pronunciation of the ground-truth token.
In order to better make use of the voting effect, researchers proposed special designs in the alignment algorithm and the model architecture.
Pronunciation-based alignment
Since the lengths of multiple candidates usually vary and the tokens from different sentences are not aligned by position, it is non-trivial to align these candidates by tokens in order to employ the voting effect. If we simply use left or right padding to ensure the same length for alignment, the information of each position in different candidates does not align, and so the voting effect is not viable. To take advantage of the voting effect, researchers proposed a novel alignment algorithm based on token matching score and pronunciation similarity score that can ensure the tokens on the same position are matched as much as possible or the pronunciations of tokens on the same position are as similar as possible if tokens are not matched.
As shown in Figure 3, compared with the naïve alignment method (padding to right), the new alignment method can: 1) align the same tokens (“B”, “D” and “F”) at the same position, 2) isolate the additional token occurring only in one candidate (“C”), and 3) keep the pronunciation similarity of the tokens on the same position as high as possible.

Candidate predictor to select candidate for decoder
There may be multiple candidates (the same as the number of source sentences), but the decoder can only take one adjusted source sentence as the input. (Since the predicted duration might be different in different candidates during inference, it is unviable to feed all adjusted candidates with different lengths into the decoder.) Thus, it is necessary to choose the appropriate source sentence to adjust and take as input to the decoder. Researchers therefore designed a candidate predictor to decide on the most appropriate source sentence. Specifically, researchers want to choose the candidate that can yield the smallest loss (i.e., the easiest candidate to correct) in the correction model.
As shown in Figure 4, the aligned beam search results are concatenated along each position, reshaped by a linear layer, and then fed into the encoder. The encoder output is concatenated with the original token embedding and fed into the predictor to predict the duration of each source token (by a duration predictor) and the loss of candidates (by a candidate predictor). The source token is adjusted according to the duration predictor and then fed into the decoder. Finally, the loss of the decoder is used as the label of the candidate predictor.

Experimental results
Table 2 shows the correction accuracy and inference latency of different correction models, based on which we have made the following observations:
Compared with the FastCorrect baseline, FastCorrect 2 can improve correction accuracy by 2.55% and 3.22% in terms of WER reduction on AISHELL-1 and the internal dataset, respectively, which shows the effectiveness of utilizing information on multiple candidates. Moreover, FastCorrect 2 is five times faster than the autoregressive model, indicating inference efficiency.
Both FastCorrect and FastCorrect 2 are open sourced here: https://github.com/microsoft/NeuralSpeech (opens in new tab). Researchers are developing FastCorrect 3 for better correction accuracy under fast inference speed.
Paper Link:
FastCorrect:Fast Error Correction with Edit Alignment for Automatic Speech Recognition
https://arxiv.org/abs/2105.03842 (opens in new tab)
FastCorrect 2:Fast Error Correction on Multiple Candidates for Automatic Speech Recognition