

Exploring MSR Asia’s contributions to ICLR 2023: From robust machine learning to responsible AI
ICLR is recognized as one of the most influential international academic conferences in machine learning. At this year’s conference, Microsoft Research Asia presented its latest research contributions in machine learning robustness and responsible AI, among other fields. Check out the following article to learn more about recent progress made in machine learning research.
Exploring the Limits of Differentially Private Deep Learning with Group-wise Clipping
Jiyan He, Xuechen Li, Da Yu, Huishuai Zhang, Janardhan Kulkarni, Yin Tat Lee, Arturs Backurs, Nenghai Yu, Jiang Bian
In this paper, researchers explored privacy protection for training data used in deep learning in an effort to ensure that one cannot infer information on individual training samples from the learned model. The paper proposes an adaptive groupwise clipping technique that breaks through the efficiency bottleneck of the differential privacy algorithm DP-SGD, making it applicable to the training of large language models like GPT-3.
Differentially Private Stochastic Gradient Descent (DP-SGD) is a general algorithm for learning with differential privacy. DP-SGD involves clipping individual gradients (referred to as flat clipping—first flattening the gradient into a vector and then clipping it), followed by adding an appropriate amount of noise.
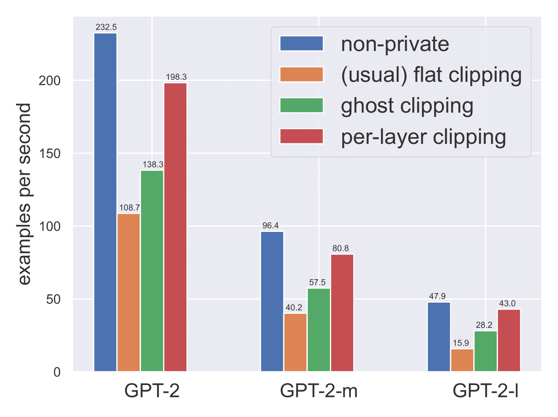
The flat-clipping strategy in DP-SGD requires 1) instantiating the gradient for each sample, 2) clipping it according to its L2 norm. This results in much higher memory cost or time overheads for DP-SGD compared to its non-private counterpart.
The first question to investigate is: Can DP-SGD maintain high efficiency in memory and time (per epoch) like non-private SGD? Researchers have affirmatively answered this question through an efficient implementation of per-layer clipping, where they clip layer-wise gradients as soon as the gradients with respect to that layer are returned from backpropagation, and then they release the space occupied by each sample gradient and continue backpropagation to the next layer of parameters. This results in private learning that is as memory-efficient and almost as time-efficient per training update as non-private learning for many workflows of practical interest (see Figure 1).
The remaining question is how to choose the clipping threshold for each layer. Simple experiments reveal that per-layer clipping with manually selected static clipping thresholds tends to underperform flat clipping. Results suggest a trade-off between efficiency and utility in DP-SGD. In this paper, researchers seek to resolve this using adaptive per-layer clipping, which adaptively estimates clipping thresholds for each layer. DP-SGD with adaptive per-layer clipping matches or outperforms flat clipping under given training epoch constraints and attains similar or better task performance with less wall time.
DP-SGD’s improvements in performance and efficiency make it possible for researchers to explore the limits of differentially private deep learning (pretrained) models. Researchers performed privacy-preserving fine-tuning on GPT-3 with 175 billion parameters. To circumvent the challenges associated with clipping gradients distributed across multiple devices, they performed groupwise clipping on the gradients of each model fragment on each device. In the case of ε=1, the privacy-preserving fine-tuned GPT-3 surpassed the performance of non-private fine-tuned GPT-2 on the summarization task.
Paper link: https://arxiv.org/abs/2212.01539 (opens in new tab)
Out-of-Distribution Representation Learning for Time Series Classification
Wang Lu, Jindong Wang, Xinwei Sun, Yiqiang Chen, Xing Xie
Out-of-distribution (OOD) generalization is one of the most important and challenging problems in machine learning. Traditional assumptions treat distribution as static, while in reality, the data distributions in the real world are dynamically changing. For instance, people’s faces, satellite images of a region, and knowledge in social networks all change over time. However, existing solutions mainly focus on handling OOD generalization under static conditions and fail to perform effectively in dynamic environments. To address this issue, researchers proposed to model OOD generalization in time series from a distribution standpoint. This is because the complexity of dynamically changing distributions can be attributed to unknown latent distributions.

In this research, researchers proposed DIVERSIFY, a general OOD representation learning framework for dynamic distributions. DIVERSIFY follows an iterative process. It first obtains the “worst-case” latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. Researchers show that this algorithm is theoretically supported. Extensive experiments were conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results show that DIVERSIFY significantly outperforms other baselines and effectively characterizes latent distributions. It can also be easily extended to other modalities such as images and audio.
Paper link: https://arxiv.org/abs/2209.07027 (opens in new tab)
Code link: https://github.com/microsoft/robustlearn (opens in new tab)
Unified Detoxifying And Debiasing In Language Generation Via Inference-time Adaptive Optimization
Zonghan Yang, Xiaoyuan Yi,Peng Li, Yang Liu, Xing Xie
Pretrained language models (PLMs) have made significant strides in natural language generation (NLG), but one issue is that they can internalize, reproduce, propagate, and even amplify harmful information existing in pretrained corpora, such as toxic language and societal biases against minority groups. As language models gradually become the foundation for various NLG applications, including chatbots and writing assistants, any harmful content that is generated could be widely propagated through frequent interactions with end-users, causing far-reaching negative impacts in human society. For example, they can incite prejudice or exacerbate inequality. Moreover, these problems do not dissipate with the increasing scale of PLMs but rather tend to deteriorate, further highlighting the necessity and urgency of developing ethical NLG methods.
Existing detoxification and debiasing techniques typically fall into two paradigms. One is domain-specific tuning, where PLMs are further trained using carefully crafted harmless data. This approach is effective but costly. The second is constrained decoding, which avoids generating harmful text by using filtering, adversarial triggers, and output distribution rectification. This is done without training or fine-tuning the model. However, these methods tend to severely hurt the quality and speed of text generation. Moreover, they treat detoxification and debiasing separately, causing the debiased models to continue to exhibit toxicity and the detoxified ones to be even more biased.

To address these challenges, researchers proposed a unified framework named UDDIA for detoxification and debiasing. This framework is based on inference-time adaptive optimization. UDDIA formalizes detoxification and debiasing by establishing a unified output distribution rectification process that aims to balance the generation probabilities of content related to different groups and minimize associated toxicity. This framework is equivalent to learning a mixed text distribution of multiple attributes, such as gender, race, toxicity, etc. UDDIA intervenes only during the inference (generation) phase by optimizing a small fraction (~1%) of parameters. It dynamically selects when to intervene and which parameters to update. Experimental results show that this framework can reduce about 40% of the toxicity and bias in the GPT-2 model, while maintaining minimal quality loss and high generation efficiency. This method represents an important stride towards ethical and responsible NLG, providing a flexible, scalable, and cost-effective solution for the safety of increasingly large LMs.
Paper link: https://openreview.net/pdf?id=FvevdI0aA_h (opens in new tab)
SIMPLE: Specialized Model-Sample Matching for Domain Generalization
Ziyue Li, Kan Ren, XINYANG JIANG, Yifei Shen, Haipeng Zhang, Dongsheng Li
This research introduces SIMPLE, an innovative and efficient method to solve the domain generalization (DG) problem found in artificial intelligence. Unlike most existing methods that fine-tune a specific pretrained model using specific DG algorithms, SIMPLE leverages a pool of diverse pretrained models without fine-tuning. Pretrained models have some generalization ability, but there isn’t a single model that can fit all distribution shifts. Researchers theoretically proved that the extent of the generalization errors depends on the fitness between the pretrained models and the unseen test distribution.
To address this challenge, SIMPLE uses model-sample matching method to dynamically recommend suitable pretrained models to predict each test sample. First, SIMPLE adapts the predictions of pretrained models to the target domain using label space transformation. Then, a matching network that knows the model specialty will select proper pretrained models based on their fitness to an out-of-distribution sample. Their corresponding predictions will be aggregated through the estimated fitness scores.
SIMPLE outperforms state-of-the-art methods by up to 12.2% on a single dataset and 3.9% on average across the common benchmark. It also improves training efficiency by more than 1,000 times compared to conventional DG methods that require pretrained model fine-tuning. In the paper, researchers also provide useful tips on how to construct a model pool to improve generalization performance.
SIMPLE offers a practical and efficient way to leverage diverse pretrained models to address the DG problem effectively. It is a promising alternative to existing DG methods that fine-tune pretrained models.


Paper link: https://openreview.net/forum?id=BqrPeZ_e5P (opens in new tab)
Project link: https://seqml.github.io/simple/ (opens in new tab)
Explaining Temporal Graph Models Through An Explorer-Navigator Framework
Wenwen Xia, Mincai Lai, Caihua Shan, Yao Zhang, Xinnan Dai, Xiang Li, Dongsheng Li
Temporal graphs are highly dynamic networks, where new nodes and edges can appear at any time. They are common in many real-world applications, such as friendship connections made in social networks and user-item interactions in e-commence sites. Many temporal graph models (e.g., Jodie, TGAT and TGN) consider both time dynamics and graph topology. Compared with static GNNs, temporal graph models learn the node representation as a function of time and then make predictions about future evolutions, such as which interaction will occur and when node attributes change.
However, these models are all black boxes and lack transparency. The process of information aggregation and propagation over a graph and the influence of historical events on a prediction is opaque. Human-intelligible explanations are critical for understanding the rationale of predictions and providing insights into model characteristics. Explainers can increase the trust and reliability of temporal graph models when they are applied to high-stakes situations, such as fraud detection and disease progression prediction. They can also help check and mitigate privacy, fairness, and safety issues in real-world applications.
While there are no methods for explaining temporal graph models, some recent explanation methods (e.g., GNNExplainer, PGExplainer and SubgraphX) for static GNNs are most relevant. These methods identify the important nodes, edges, and subgraphs for predictions by perturbing the input of GNN models. However, they cannot explain a well-trained temporal graph model due to their inability to capture the temporal dependency mixed with the graph topology.
Hence, researchers proposed T-GNNExplainer, an instance-level model-agnostic explainer for temporal graph models. For any prediction of a target event, the goal is to find out important events from candidate events that lead to the model’s prediction of occurrence (or absence). Candidate events are those that have previously occurred and that satisfy spatial and temporal conditions: they are in the k-hop neighborhood based on the message passing mechanism, and their timestamps are close to that of the target event. T-GNNExplainer combines the advantages of search-based and learning-based GNN explainers. Researchers pretrained a navigator in advance to learn the inductive relationship between a target event and its candidate events, then utilized MCTS to explore the best combination of candidate events given any new target event. The navigator helps to guide the search process, significantly reducing search time and improving performance.
Researchers evaluated T-GNNExplainer on both synthetic and real-world datasets for two typical temporal graph models (TGAT and TGN). On synthetic datasets, researchers simulated temporal events using the multivariate Hawkes process and pre-defined event relation rules. The highly accurate explanations generated demonstrate that T-GNNExplainer is able to find an exact influential event set. Since the ground truth for real-world datasets is unknown, researchers used the fidelity-sparsity curve to evaluate the superiority of T-GNNExplainer compared with baselines. Furthermore, a case study on synthetic datasets was conducted to illustrate the practical events found by T-GNNExplainer.

Paper link: https://openreview.net/forum?id=BR_ZhvcYbGJ (opens in new tab)