

Exploring Media Foundation: 2024 Microsoft Research Asia StarTrack Scholars Program Elevates Multimodal AI Research
In a groundbreaking move, Microsoft Research Asia’s prestigious StarTrack Scholars Program has officially taken flight, extending a global invitation to brilliant young minds for an immersive three-month research visit. Picture this: collaboration with elite researchers, a deep dive into the Microsoft Research environment, and a valuable opportunity to transform academic brilliance into real-world impact. But here’s the exclusive: Amidst the program’s three pivotal research themes, the spotlight is now on Media Foundation—a catalyst for innovation in the realms of media and technology. Brace yourself for an in-depth exploration into the heart of the 2024 StarTrack Scholars Program. For a comprehensive experience, visit our official website: Microsoft Research Asia StarTrack Scholars Program – Microsoft Research
The saga continues! Stay tuned for an exclusive series on the Microsoft Research Asia StarTrack Scholars Program, where we unravel the intricacies of the research themes that are steering the 2024 program towards a future defined by technological excellence. Join us as we set sail towards the stars and reshape the narrative of tech innovation!
Unlocking the Potential of AI in Observing and Understanding the Real World
In the pursuit of artificial intelligence mirroring human capabilities in extracting knowledge and intelligence from real-world media, Microsoft Research Asia has set its sights on innovating within the realm of Media Foundation. This groundbreaking research theme, as one of the three core focuses of the 2024 StarTrack Scholars Program, aims to provide fresh insights for the study of multimodal large models.
“We aspire for artificial intelligence to emulate humans by acquiring knowledge and intelligence from various media sources in the real world,” said Yan Lu, Partner Research Manager, Microsoft Research Asia. “To achieve this goal, we must transform the complex and noisy real world into abstract representations capable of capturing essential information and dynamics. The exploration of Media Foundation serves as a new breakthrough in the synergy of multimedia and artificial intelligence, offering novel perspectives for the research on multimodal large models.”
Breaking the Barrier Between the Real World and Abstract Semantic Space
Over the last 70 years since the inception of the term “artificial intelligence” at the Dartmouth Conference in 1956, advancements in technology and resources have propelled AI to unprecedented heights. With the recent surge in Large Language Models (LLMs), such as ChatGPT and DALL-E, showcasing remarkable progress in natural language understanding, speech recognition, and image generation, the potential for AI to observe, learn, understand, reason, and create in the real world has become more apparent than ever.
However, despite these strides, a substantial gap remains between the cognitive abilities of AI and humans. While the human brain can interpret a vast array of phenomena from the physical world—such as videos, sounds, language, and text—and abstract them into preservable and accumulative information, multimodal AI models are still in their early stages of development when it comes to tackling universal tasks.
The ambition is for AI to learn and iterate from real-world data. The challenge lies in bridging the gap between the complex, noisy real world and the abstract semantic world where AI operates. Can we construct another language parallel to natural language for different types of media information? The answer to this question, according to Yan Lu and colleagues at Microsoft Research Asia, lies in researchers’ dedication to constructing a comprehensive Media Foundation framework, starting with the neural codec. This framework aims to extract representations of different media content, enabling AI to understand the semantics of the real world and, in turn, bridging the gap between reality and abstract semantics for multimodal AI research.
Humans excel as learners due to their ability to observe and interact with the physical world through various senses—sight, sound, touch, and speech. The aspiration is to replicate this human characteristic in AI, enabling it to learn and iterate from rich real-world data.
While most AI models are built on top of Large Language Models (LLMs) that use abstract, concise text expressions to understand the world, there is a need for efficient methods to transform complex and noisy signals from video and audio sources into abstract representations that capture the essence and dynamics of the real world.
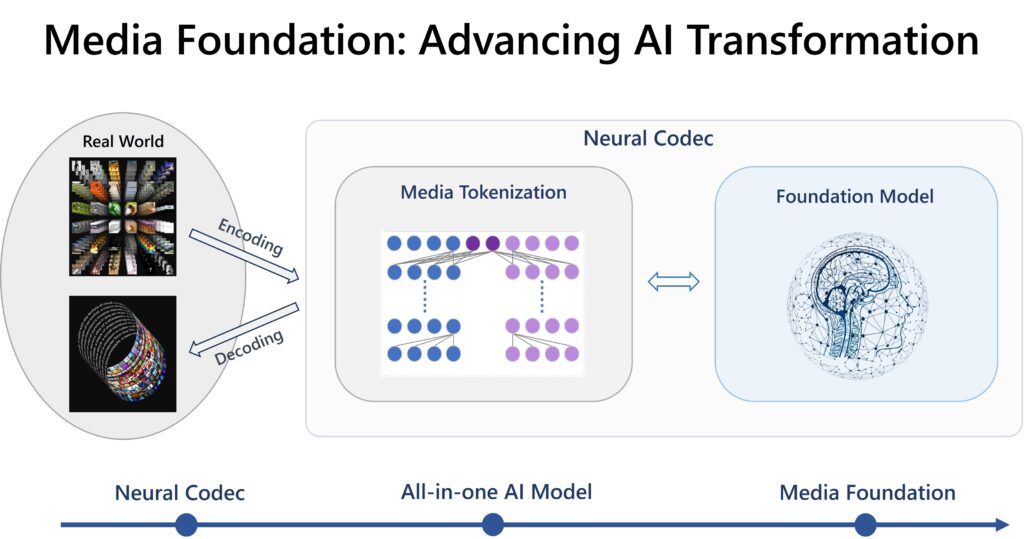
The Media Foundation framework, as envisioned by Yan Lu and his team, consists of two components: the online media tokenization and the offline foundation model. The online model dynamically converts multimedia information into compact, abstract semantic representations for AI to observe and interact with the real world. Meanwhile, the offline foundation model is constructed using extracted media tokens from the real world and predicts dynamics through offline learning. The efficiency and near-lossless compression of real-world dynamics are essential sources of AI intelligence, whether learning from text or audio and video signals.
Neural Codec: Constructing Abstract Representations for Multimedia
Media Foundation is envisioned as a comprehensive framework comprising online media tokenization and offline foundation models. These components, driven by the neural codec, aim to efficiently convert different modalities of media signals into compact and semantic representations, constructing an abstract representation of the real world and its dynamics.
The development plan spans three phases: firstly, training initial encoder and decoder models for each modality; secondly, building foundation models for each modality and further optimizing the encoder and decoder; and lastly, learning cross-modal correlations and ultimately constructing the final multimodal foundation model. This dynamic media representation, in conjunction with the multimodal foundation model, forms Media Foundation, providing a new perspective for the study of multimodal artificial intelligence.
As previously discussed, the abstract semantic representation is more compact and concise, while video and audio signals are complex and noisy. Can Media Foundation compress the dynamics of the real world efficiently and with minimal loss? This challenge has spurred the team to develop a new neural codec framework dedicated to constructing abstract representations for video, audio, and their dynamics.
Efficient Neural Audio/Video Codec Development: Paving the Way for Innovative Applications
Over the past few years, Yan Lu and his colleagues have focused on developing efficient neural audio/video codecs and have made exciting progress. Disrupting traditional codec architectures through deep learning, the team has achieved lower computational costs and superior performance.
In the realm of neural audio codec development, they achieved high-quality speech signal compression at 256bps, realizing disentangled semantic representation learning through information bottleneck at an extremely low bitrate. This breakthrough not only holds significance at the multimedia technology level but also empowers various audio and speech tasks, such as voice conversion or speech-to-speech translation.
Additionally, the team developed the DCVC-DC (Deep Contextual Video Compression-Diverse Contexts) neural video codec. This codec transforms different modules and algorithms traditionally combined through rule-based approaches in codec design into an automated deep learning process. This innovation significantly enhances video compression ratio and surpasses all existing video codecs. Due to the comprehensive and collaborative nature of Media Foundation, the team is currently making substantial modifications to the DCVC-DC codec.
Exploring New Possibilities Beyond Implicit Text Language
The newly developed neural codec fundamentally alters the modeling of different types of information in the latent space, achieving higher compression ratios. For multimodal large models, this approach enables the transformation of visual, language, and audio information into neural representations in the latent space. Unlike the simple sequential descriptions in natural languages, these multimedia representations conform to natural laws and support a wider range of applications.
The team’s exploration validates the feasibility of constructing a new Media Foundation based on video and audio information, offering a brand-new perspective for AI development. While natural language has proven to be effective in constructing AI, having to always transform complex multimedia signals into text can be laborious and limit its development. Constructing a Media Foundation based on neural codecs could provide a more effective approach.
Although the pathways for developing multimodal large models through Media Foundation and natural language models differ, both approaches hold irreplaceable value for the development of artificial intelligence. If AI-learned multimedia representations are considered a parallel “language” to natural language, then large multimodal models can be seen as “large multimedia language models.” The development of the neural codec is expected to play a crucial role in driving the evolution of Media Foundation, with its media foundation models and large language models collaboratively shaping the future of multimodal large models, unlocking the full potential of artificial intelligence.
The team will continue to explore various modeling approaches in the latent space for multimedia information using neural codecs. Media Foundation will serve as their guiding principle, presenting myriad possibilities at every entry point. As we navigate the intricacies of constructing a comprehensive Media Foundation framework, we extend a call to brilliant young minds passionate about reshaping the future of artificial intelligence.
We invite talented young scholars from around the world to apply for the 2024 StarTrack Scholars Program, which offers an exciting opportunity to collaborate with our esteemed researchers, led by Yan Lu. Engage in a transformative three-month research visit, immersing yourself in the development of neural codecs and the exploration of new possibilities beyond implicit text language. Work alongside our dedicated team, including Xiulian Peng, Cuiling Lan, and Bin Li, as we bridge the gap between the complex real world and abstract semantic space. The Media Foundation framework is not just a research endeavor; it’s a journey toward unlocking the full potential of artificial intelligence in observing and understanding the real world. Visit our official website for more details on the application process and eligibility criteria: Microsoft Research Asia StarTrack Scholars Program – Microsoft Research
References:
- Jiang, X., Peng, X., Zhang, Y., & Lu, Y. (2023). “Disentangled Feature Learning for Real-Time Neural Speech Coding.” In ICASSP 2023 – 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). Rhodes Island, Greece. DOI: 10.1109/ICASSP49357.2023.10094723 (opens in new tab). Access the paper (opens in new tab)
- Li, J., Li, B., & Lu, Y. (2023). “Neural Video Compression with Diverse Contexts.” In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 22616-22626). Vancouver, BC, Canada. DOI: 10.1109/CVPR52729.2023.02166 (opens in new tab). Access the paper (opens in new tab)
- Lu, Y. “Media Foundation: Opening New Perspectives on Multimodal Large Models (媒体基础:打开多模态大模型的新思路).” Microsoft Research Asia WeChat Account, October 12, 2023, 5:59 PM, Beijing. Access the article (opens in new tab)
Theme Team:
Yan Lu (Engaging Lead), Partner Research Manager, Microsoft Research Asia
Xiulian Peng, Principal Research Manager, Microsoft Research Asia
Cuiling Lan, Principal Researcher, Microsoft Research Asia
Bin Li, Principal Researcher, Microsoft Research Asia
If you have any questions, please email Ms. Beibei Shi, program manager of the Microsoft Research Asia StarTrack Scholars Program, at [email protected]