

Since 2019, researchers at Microsoft Research Asia have been exploring Document AI and have completed a series of work on LayoutLM/LayoutLMv2/LayoutXLM, TrOCR, MarkupLM, etc., achieving breakthroughs in a range of typical tasks such as object detection, information extraction, and document classification. However, most of the vision models used have been those trained on general domains, such as ResNet, ViT, etc., rather than document-specific vision models. This has led to the problem of domain shifts and mismatches when encoding document images.
In the document image domain, large-scale annotated data such as ImageNet does not yet exist, and so large-scale supervised pre-training cannot be carried out. Moreover, although some of the work has attempted to explore weakly supervised training of document understanding models, the datasets used in these approaches have been mostly derived from academic papers with similar templates and layouts and are quite different from the forms, receipts, reports, and so on that are more commonly found in real-world applications. Therefore, large-scale unsupervised pre-training models for document images are highly desirable and can bring performance improvements to existing methods.

To address these issues, researchers at Microsoft Research Asia have developed a new DiT model based on the current advanced Vision Transformer architecture, the paper has been accepted by ACM Multimedia 2022. The training of DiT does not rely on any labeled data but follows the unsupervised pre-training method for BEiT, Masked Image Modeling, to make full use of the large number of unlabeled document images. In this method, the researchers first resize a document image to 224×224 and then slice it into a sequence of 16×16 patches, for which a representation of each patch is obtained via the encoder part. Also, the image is tokenized with a pre-trained dVAE to obtain the index of each patch in the codebook. By randomly masking some patches in the sequence and reconstructing the masked patches by predicting their indices with the information from the remaining patches, the model is able to learn a generalized document understanding ability from unlabeled document images.
To validate the performance of DiT, the researchers conducted experiments on four different downstream tasks, including document image classification, document layout analysis, table detection, and text detection. Experimental results show that DiT significantly outperforms models trained on general images, demonstrating its effectiveness.
Model Pre-training
The model structure of DiT is consistent with ViT and adopts the native Transformer structure as its skeleton network. First, the input document image is split into multiple non-overlapping patches, and a sequence of patch embeddings is obtained by a simple linear projection. After adding the one-dimensional position embeddings, the sequence is fed into a series of consecutive Transformer blocks with multi-head attention to obtain the final representation of each patch. Inspired by BEiT, DiT also employs Masked Image Modeling (MIM) for pre-training. In this step, the input image is viewed in two perspectives, both as a patch sequence and as vision tokens. The model needs to encode the masked patch sequence and predict the visual tokens of the masked patches. Figure 2 illustrates this model structure and the overall pre-training steps.

The dVAE tokenizer used in the training of BEiT was derived from DALL-E, which was trained from a dataset of 400 million general images. Using the same tokenizer directly for training DiT would lead to domain inconsistency, so the researchers retrained a new dVAE tokenizer on the IIT-CDIP document image dataset. Figure 3 shows the reconstruction results of document images using both the tokenizer trained on IIT-CDIP data and the DALL-E tokenizer. It can be seen that the reconstructed images obtained using the new tokenizer have sharper edges, while the images obtained using the DALL-E tokenizer are blurrier.

Fine-tuning downstream tasks
The downstream tasks used to validate DiT include document image classification, document layout analysis, table detection, and text detection. These can be classified into two main task categories: image classification and object detection.
For the image classification task, a simple mean pooling layer is used to integrate the representations of the patch sequence into a global representation, which is fed into a simple linear layer for classification.
For the object detection tasks, as shown in Figure 4, researchers use Mask R-CNN as the default detection framework and then further use the more advanced Cascade R-CNN for some tasks. Based on existing work, the researchers designed corresponding scaling modules in the four different DiT layers to adapt to the multi-scale FPNs required in the detection algorithm. Specifically, if the model has d layers, the output size of the 3/d layer is enlarged by a factor of 4, the output size of the 2/d layer is enlarged by a factor of 2, the output of the 2/3d layer remains the same, and the output size of the last layer is reduced by a factor of 2. These scaled feature maps are then fed into FPN in the detection framework.

Experimental results
1. Pre-training
DiT has two versions, a base size and a large size, and both were trained on the IIT-CDIP Test Collection 1.0 dataset. 42 million document images were obtained after slicing the multi-page documents in the dataset into single pages. During the pre-training process, the researchers used random scaling and cropping for data augmentation.
2. Document Image Classification
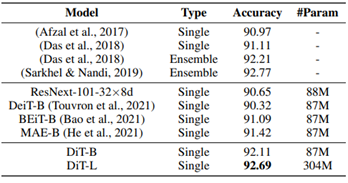
The document image classification task uses RVL-CDIP as the test dataset, containing 400,000 document images, each of which belongs to one of the 16 common document types. Experimental results are shown in Table 1. It can be seen that DiT shows significant performance improvement in the single model scenario over previous methods. DiT-L has achieved results that are even comparable with previous ensemble models.
3. Document layout analysis
The document image classification task uses PubLayNet as the test dataset, containing over 360,000 document images. This task requires the model to detect common document elements from images, such as text, titles, lists, figures and tables. Experimental results are shown in Table 2, where DiT not only far exceeds existing SOTA methods, but also significantly outperforms various baseline models of vision Transformer. When a more advanced detection framework (e.g., Cascade R-CNN) is used, DiT achieves more accurate detection results.

4. Table detection
The table detection task uses ICDAR 2019 cTDaR – TrackA as the test dataset. This task requires the model to detect all tables in an image and to cover both modern and archival documents. The modern documents used contain 600 training samples and 240 test samples, consisting of screenshots of various types of PDF files. The archival documents used consist of 600 training samples and 199 test cases and are composed of older handwritten archival images. Because there is a significant difference in backgrounds between the archival files and the pre-training data, adaptive binarization pre-processing needs to be carried out before finetuning (as shown in Figure 5). Experimental results are shown in Table 3. DiT achieves higher scores than previous SOTA and baseline models on both branches of the task and is able to perform better after switching to the more advanced Cascade R-CNN.


5. Text detection
The text detection task uses FUNSD’s OCR text recognition branch as the test dataset and requires the model to detect text bounding boxes in document images. This task contains 150 training cases and 49 test cases. Experimental results are shown in Table 4. DiT’s detection results are much better than those of DBNet, a commonly used online OCR engine, and an existing commercial OCR engine, and it also performs significantly better than the chosen baseline models. Researchers further trained DiT on a synthetic dataset containing 1 million document images, and this further improved the text detection performance of the model.

Future work
To fill the current gap in unsupervised pre-trained document vision models, researchers at Microsoft Research Asia have proposed and trained the DiT model, which leverages large-scale and diverse unlabeled document image data and is therefore ideal for vision models in a variety of downstream document tasks. DiT outperforms several state-of-the-art baseline models in tasks such as document image classification, document layout analysis, table detection, and text detection, all with results that reach the latest SOTA. Currently, the DiT model and related codes have been open-sourced (code link: https://aka.ms/msdit) to facilitate further research in the field of document AI.
In the future, researchers at Microsoft Research Asia will try to train DiT on larger datasets and further improve performance on various downstream tasks. In addition, new visually rich document understanding models, such as LayoutLMv3, may also adopt DiT as their basic vision models, thereby building a unified framework for computer vision and natural language understanding applications in the field of document AI.
Paper: https://arxiv.org/abs/2203.02378 (opens in new tab)
Code&Models: https://aka.ms/msdit (opens in new tab)