

For more than a quarter century, we have lived a life where our online activities are closely monitored, collected, and exploited by internet giants to offer useful services without charging fees. Today, it is unfathomable to have to pay for Apple’s Facetime, Google’s Hangout, Facebook’s Messenger or What’s App, etc., the same way that we have to pay heftily to our wireless providers for the similar services in phone calls and text messages. These internet businesses prosper because the user data are worth a lot in our connected lives. Aside from creating detailed user profiles to place more targeted advertisements, the data holds the keys to identifying trends and project needs for new products and services.
One example is Google Flu Trends (GFT) which made headlines around the world in February 2013. It was reported that web search queries, with their timestamps and locations, could serve as a good indicator of the flu epidemics. Unfortunately, it was later found (opens in new tab) that GFT’s predictions often have a wide gap from the Center of Disease Control (CDC) data, even though GFT was specifically trained on CDC reports. Nevertheless, the “wisdom of the crowd” hidden in search queries is certainly valuable and a recent approach (opens in new tab) finds it beneficial to combine search data with electronic health records to improve the prediction accuracy.
To be sure, web search data are tricky to use correctly, especially in reliably tracking epidemics. At the time of writing, COVID-19 is rampaging around the world; with Italy and China both having to take drastic measures, such as locking down cities and cancelling schools to slow down the infections. In Microsoft’s backyard the city of Kirkland, made famous by Costco as its store brand, has seen deaths exceeding 25 with worrisome evidence of community spread since the first confirmed case was reported on January 21st, 3 weeks after the outbreak was noticed in Wuhan China and one day after China’s CDC declared an emergency.
According to Google Trends, however, search volume about coronavirus was insignificant until the day China declared the emergency, but the interests subsided in 10 days. For the first three weeks of February, the query volume continued to drop. It was not until February 21st, 10 days after the official name COVID-19 was announced by the World Health Organization (WHO), did the search query start to increase again, as can be seen in the Figure below. To ensure the trend plot is interpreted correctly, we contrast the search for “coronavirus” with “google.” The latter query is likely a result of a portion of internet users typing “google” into their web browser address bar, indicating a search intent. Nevertheless, it tracks the daily search activities and shows the cyclic nature of the search queries. The activity-normalized curve for “coronavirus” is shown as the dotted line against the secondary axis in the Figure.

In the meantime, the research community has no illusions of the danger this novel coronavirus can pose to the world. Articles sounding the alarm began to be published in the journals the second week of January, one full week before China’s emergency declaration. Scientific activities prior to January 20th include events highlighted below:
| Date | Events |
| 12/27/2019 | As recounted in this JAMA paper (opens in new tab), China CDC was first alerted 4 cases of unusual pneumonia in Wuhan, China |
| 12/31/2019 | Wuhan’s health commission disclosed (opens in new tab) that 27 people, all having visited a local seafood market, had developed symptoms of a viral pneumonia. The public was advised to avoid crowded areas with poor air circulation, wear masks when going out, but there were no reasons to be alarmed. WHO was notified (opens in new tab) of the outbreak on the same day and the seafood market was closed the next day. |
| 1/7/2020 | Chinese authorities conducted genome sequencing and identified the disease was caused by a novel coronavirus after ruling out previously known coronaviruses that caused SARS (opens in new tab), MERS (opens in new tab), and many others (opens in new tab). |
| 1/9/2020 | WHO announced (opens in new tab) the discovery of a novel coronavirus by Chinese authorities, but stated the virus “does not transmit readily between people”. |
| 1/12/2020 | China reported (opens in new tab) 1st death out of 41 confirmed cases and shared the genetic sequences with WHO for other countries to develop diagnostic kits. |
| 1/14/2020 | A paper (opens in new tab) published in the International Journal of Infectious Diseases (opens in new tab) uses the term 2019-nCov to refer to the novel coronavirus. 7 of the 12 authors are members of the Pan-African Network on Emerging and Re-emerging Infections funded by European Horizon 2020. |
| 1/15/2020 | WHO reported (opens in new tab) the first confirmed case in Japan and suggested the possibility of human-to-human transmissions after a few cases with no link to the seafood market were found in China. |
| 1/17/2020 | An article (opens in new tab) in Science (opens in new tab) cautioned the spread of the virus after a tourist in Thailand was confirmed to be infected. Family Practice News reported (opens in new tab) 3 US airports started screening travelers from Wuhan China as soon as US CDC introduced the measure (opens in new tab). |
| 1/18/2020 | Journal of Hospital Infection (opens in new tab) made available online this paper (opens in new tab) outlining measures to prevent hospital outbreak for the novel coronavirus. The article is officially scheduled to appear in the journal’s March 2020 issue. |
| 1/19/2020 | A paper (opens in new tab) proposing a mathematical model of the novel coronavirus is published on bioRxiv. The model assumes animal-to-human transmission. |
| 1/20/2020 | Both BMJ (opens in new tab) and Science (opens in new tab) reported surging cases of the virus infection in this (opens in new tab) and this (opens in new tab) article. Web search on this topic started to appear according to Google Trends. |
With editors prioritizing the reviews and publications of COVID-19 papers, the volume of publications on this topic quickly rises. Furthermore, almost all academic publishers have dropped the paywalls on COVID-19 papers, accelerating the dissemination of the scientific discoveries and the citations to these articles. In total, more than 920 articles have been published in the crucial month between January 14 and February 14, one week ahead of the turning point in Google Trends. The collective responses of the scholarly community to COVID-19 are captured in the remarkable publication node growth and the citation edges in Microsoft Academic Graph (MAG), as can be seen below:
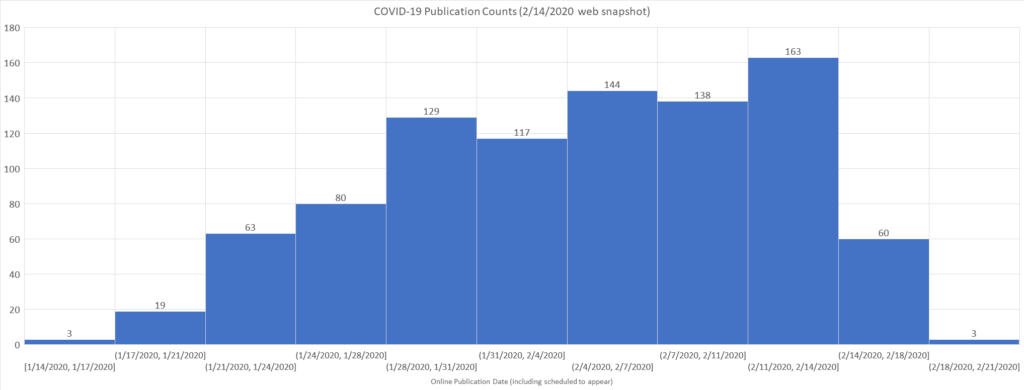
These behavioral changes have significant impacts on MAG. First, the fast appearing publications have led our machine readers to conclude not one, but two new concepts have emerged under the existing concept “coronavirus (opens in new tab)” (MAG Id=2777648638) and “infectious diseases (opens in new tab)” (MAG Id=524204448). Based on the operations described in our recent paper (opens in new tab), the new concept under the coronavirus is called “Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2)”, or simply “sars-cov-2 (opens in new tab)” (MAG Id=3007834351), and is mapped to this Wikipedia page (opens in new tab). The other new infectious disease is unsurprisingly called “Coronavirus disease 2019 (COVID-19)”, or simply “covid-19 (opens in new tab)” (MAG Id=3008058167), and is mapped to the corresponding Wikipedia page (opens in new tab). Note that the subtle distinction between a disease and its cause is an ongoing issue for our machine learning algorithm. As described in the paper, the natural outcome based on the language and the network similarities (opens in new tab), is to follow the classifications from the authoritative webpages which, in this case, are the two Wikipedia articles that make the distinction. However, as described in our recent post (opens in new tab), we also program our system to be as consistent as the Unified Medical Language System (UMLS) (opens in new tab), where such distinctions are sometimes not made (e.g., the “HIV/AIDS (opens in new tab)” concept originated from UMLS (opens in new tab) lumps the disease AIDS and its cause HIV together). The differences among the authoritative sources we use lead to inconsistencies in our taxonomy. We are anxiously waiting to see how our system will resolve this issue by itself after more publications and citations are observed in the future.
Secondly, the rapid rise of citation activities among these papers has also boosted their saliency scores, which are an indicator that predict the likelihoods of papers to receive citations in the next 5 years. As explained in this (opens in new tab) and this paper (opens in new tab), saliency uses the same reinforcement learning (RF) algorithm as in Alpha Go and other video game playing systems to anticipate the next moves from humans. Instead of sending the RF learning agents into parallel universes to play thousands of games simultaneously, here we send the RF agents to travel back and forth in time to acquire the best strategy in predicting future citations. In this sense saliency is a leading rather than a lagging indicator, e.g. the citation count, of the research impact of any given paper. Due to the flurry of citations among them a mere month is all it takes for the COVID-19 papers to dominate the search results for the query “coronavirus china (opens in new tab)”, even though they all have yet to receive their full recognitions and their citation counts are much lower than other coronavirus papers published years ago. To see the differences in rankings by saliency and by citation counts, snapshots of the search results ranked by the saliency (relevance) and the citation counts based on data up until February 14, 2020 are shown below. Note that the term “COVID-19” was adopted by WHO (opens in new tab) only on February 11, the same day the Coronavirus Study Group published this naming paper on bioRxiv (opens in new tab) proposing to use SARS-Cov-2 instead of 2019-nCov. Papers accepted for publications prior to this date cannot be retrieved with these keywords. However, these early publications are detected as discussing topics about “coronavirus” and “china (opens in new tab)” (MAG Id = 191935318). The query is thus useful in finding these early publications.
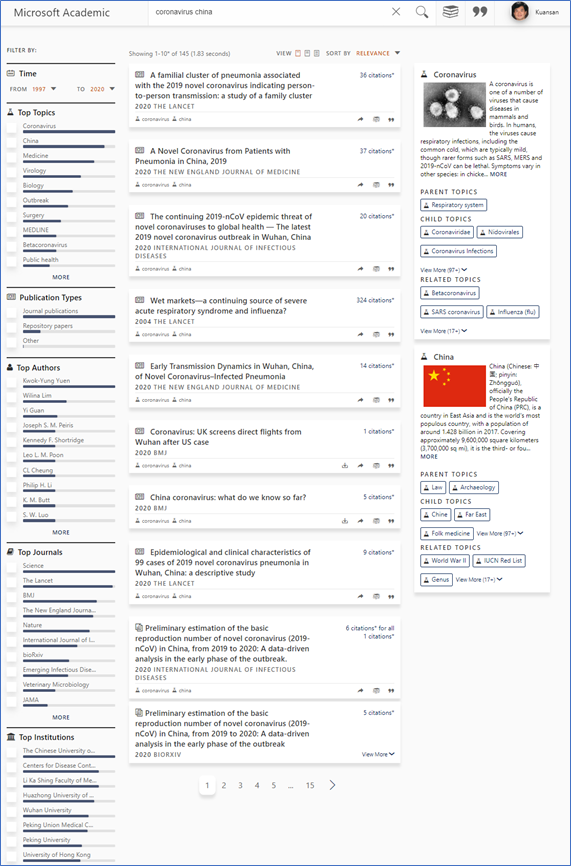
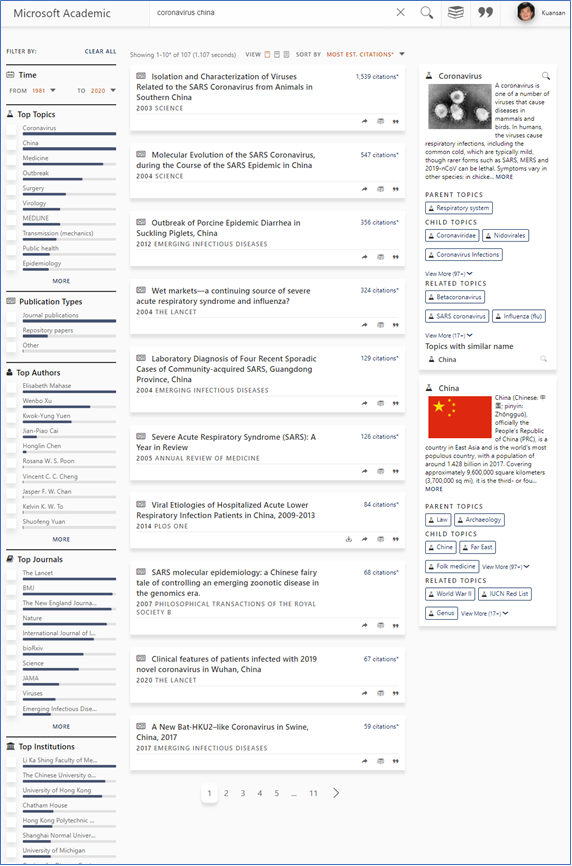
So how effective are search and click behaviors underlying Google’s and Bing’s rankings? Our experience shows that searching behaviors are useful in capturing general consumer interests. However, for cases such as pandemics that require expert knowledge, the consumer behaviors are in fact a lagging indicator. For this reason, and to respect the privacy of our users, Microsoft Academic is a search engine that does not include user private data such as browsing and clicking activities in the search ranking. We can, however, compare the rankings in the equivalent Google Scholar to understand the effectiveness of using search behaviors. Indeed, when the search volume on the topic of “coronavirus” was not enough, older papers that have accumulated larger citation counts were ranked higher. By the time of February 18, 2020, however, some papers about COVID-19 started to make it to the top 10 search results. To be fair, by this time most papers have included the terminology “2019-nCov” to clarify which novel coronavirus the contents are about. As the screenshots below show, Google Scholar did an excellent job for this query.
The field of study known as infodemiology (opens in new tab), established in 2002 based on the insight of Gunther Eysenbach (opens in new tab)’s ground breaking paper (opens in new tab), has been studying the utilities of search queries and social media activities in capturing public health (opens in new tab) issues in a more accurate and timely manner. To the best of our knowledge (based on this query (opens in new tab)), we believe we are the first to observe scholarly communication activities as a potential resource in tracking epidemics. More research is needed, but one thing is for sure: without the scientists actively submitting new findings and editors prioritizing their publications, we wouldn’t have been able to report this useful dataset. The credit should really go to the collaborative instincts and the scholarships of the research community that we are very proud to be a member of.
Happy researching!

