

Microsoft Academic Graph (MAG) explores how we can harness the power of modern machine cognition capabilities to capture the accumulated knowledge as recorded in the academic publications and patent filings of the last two hundred years. Since MAG launched in late 2015, more than 170 research projects and systems (opens in new tab) have been able to use this rich knowledge base to try out new ideas and release new products. There are two major ways of getting a copy of MAG. First, MAG is a major component of the Open Academic Graph (opens in new tab) developed by Tsinghua University, where advanced entity conflation algorithms have been applied to merge the knowledge in MAG and Tsinghua’s AMiner (opens in new tab) graph. This latest version of the Open Academic Graph uses a snapshot of MAG taken in late November 2018, and we’re thrilled to make it available as a free download.
Research never stops, however. More than 1 million publications are being added to MAG each month (more on this later). If your project needs to access the most current data and cannot wait for the annual updates of Open Academic Graph, we are also making a more frequently updated MAG available through Azure cloud replication, as described in the MAG online document (opens in new tab). This online version enables users to conduct their research directly in the cloud and leverage the big data analytics Azure offers. We have included a link to the Azure price calculator in the document so that you can estimate the storage and networking costs that a project will incur on Azure.
While the Azure prices on storage, computation, and read/write operations are clearly listed, sometimes it’s not a trivial task to estimate charges. How much cloud resource a typical analytical project will consume, and what degree of parallelism that you specify to execute the task impact costs. We hope the following two examples can give you a better reference point to estimate the Azure charges you may encounter.
First, let’s consider a very rudimentary “Hello World” type of task that analyzes the growth in scholarly communication activities for the years that MAG has data for. The task is rather straightforward: we just have to go over all of the publications and tabulate them based on their year of publication. Using the built-in Azure Data Lake Analytics language called U-SQL (opens in new tab), the core of the analytic script amounts to two statements:
@paperCitationCounts =
SELECT
Year,
COUNT(*) AS PaperCount,
SUM(EstimatedCitation) AS CitationCount
FROM @magPapers
GROUP BY Year;
OUTPUT @paperCitationCounts
TO @outStream
ORDER BY Year ASC
USING Outputters.Csv(quoting : false);
The first statement uses a variable @magPapers to refer to the Papers.Txt data stream in MAG that contains all the information for each publication. If you have first run the CreateFunction.usql script that comes with your MAG distribution on each snapshot, you can easily specify the stream by using the single statement:
@magPapers = Papers(@uriPrefix);
with @uriPrefix being “wasb://” + @dataVersion + “@” + @blobAccount + “/”, where @dataVersion is the name of the MAG snapshot you’d like to use (for example, the November 29, 2018 snapshot of MAG, also used in the Open Academic Graph, is “mag-2018-11-29”), and @blobAccount is the Azure Blob Storage account to which you have asked us to send the MAG data. Using the default five degrees of parallelism (or in Azure’s parlance, using 5 AUs), the script takes 4 minutes and 17 seconds to finish, for a cost of U.S. $.38:
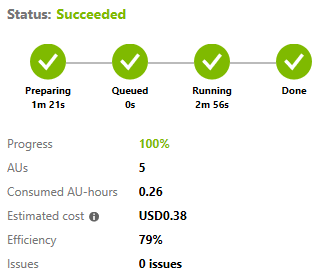
The detailed cloud resource consumption as reported in Azure portal is:
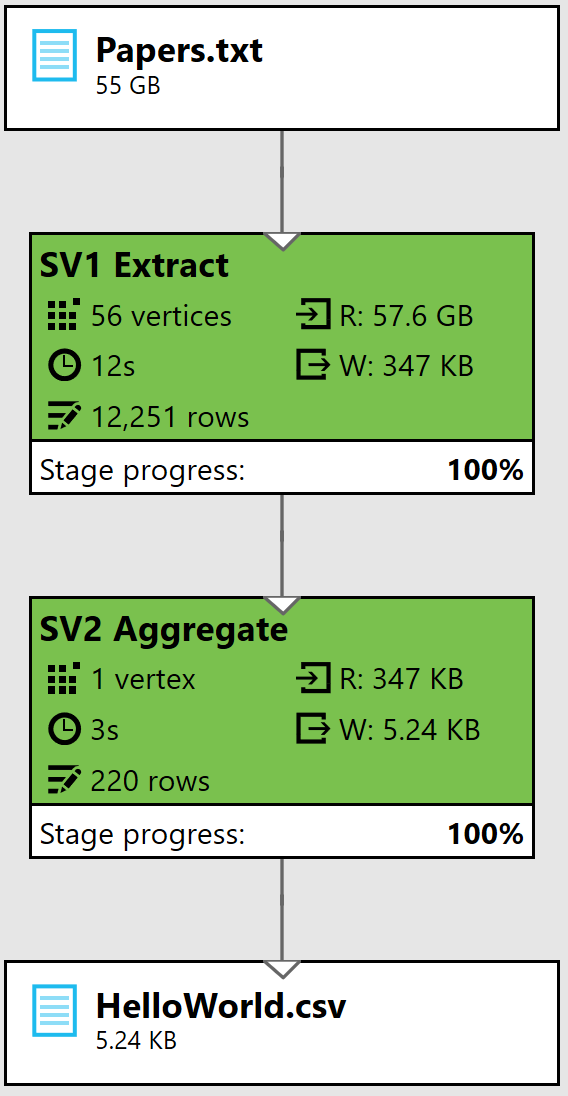
Obviously, you can use fewer AUs and wait for longer to reduce the cost down from 38 cents, but we think 38 cents is quite a bargain because you get to generate a chart like the following one, based on the data output from the script:
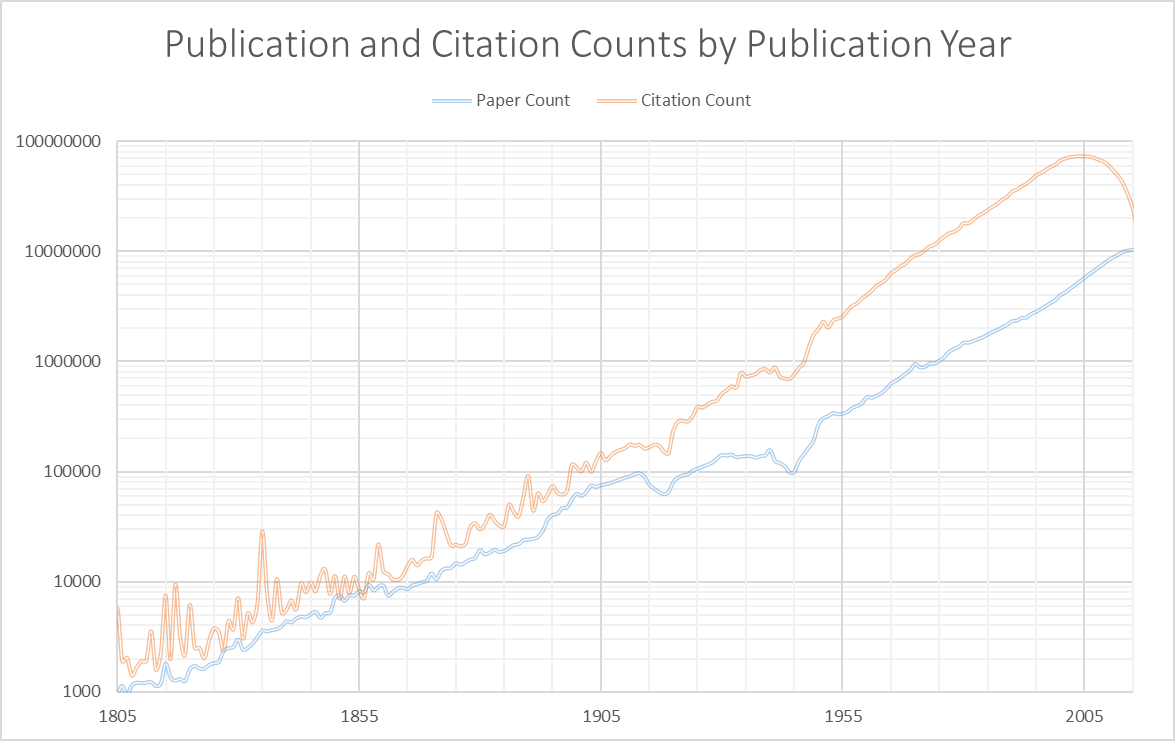
Here, we can see that the academic community has been on an exponential growth path (note the vertical axis is in logarithmic scale!), both in terms of publications and citations, for the past two hundred years. Both pace and the rate of growth show no signs of slowing. The only periods that we see dips are during the two world wars, and the publication growth seems to be flat during the Great Depression in the 1930s. On average, recent papers receive more citations than the ancient ones, judging by the widening separations of the two curves. The total citation count begins to decay after year 2005, suggesting that average papers take more than a decade for their due citations to be properly observed and included into MAG.
Tabulating the publication and citation counts over the year is indeed really simple. How about another common task we are frequently asked by our users, where they would like to track a list of authors by their impact in the research community and compute their h-index (opens in new tab)? This task is slightly more complex than the previous one in that we have to first look up the authors from the list in the MAG, then retrieve all the publications each author has in order to compute their impact metric. The script involves a few INNER JOIN commands in U-SQL for looking up data from MAG; and to compute h-index, we have to create a citation histogram for each author. The core logic can be realized as follows:
@targetAuthors =
EXTRACT
AuthorName string
FROM @targetList
USING Extractors.Tsv();
// Lookup Author IDs for each name
@targetAuthorsWithIDs =
SELECT
A.AuthorId,
T.AuthorName
FROM @targetAuthors AS T
INNER JOIN @authors AS A
ON T.AuthorName == A.DisplayName; // Can alternatively use C# string match functions
@affiliationAuthorPapers =
SELECT DISTINCT // Condense author with multiple affiliations into a single row
A.AuthorId,
A.AuthorName,
T.PaperId
FROM @targetAuthorsWithIDs AS A
INNER JOIN @paperAuthorAffiliation AS T
ON T.AuthorId == A.AuthorId;
// Get citation count from Papers table
@authorPaperCitation =
SELECT
A.AuthorName,
A.PaperId,
P.EstimatedCitation,
P.Rank
FROM @affiliationAuthorPapers AS A
INNER JOIN @papers AS P
ON A.PaperId == P.PaperId;
// Compute Paper Rank using citation count
@authorPaperRankByCitation =
SELECT
PaperId,
AuthorName,
EstimatedCitation,
Rank,
ROW_NUMBER() OVER(PARTITION BY AuthorName ORDER BY EstimatedCitation DESC) AS PaperRank
FROM @authorPaperCitation;
// Compute h-index and total citation count
@authorHIndex =
SELECT
AuthorName,
COUNT(*) AS PaperCount,
SUM(EstimatedCitation) AS CitationCount,
MAX((EstimatedCitation >= PaperRank) ? PaperRank : 0) AS Hindex,
SUM(Math.Exp(-1.0*Rank/1000)) AS Saliency
FROM @authorPaperRankByCitation
GROUP BY AuthorName;
OUTPUT @authorHIndex
TO @outAuthorHIndex
ORDER BY Saliency DESC, AuthorName ASC, Hindex DESC
USING Outputters.Tsv(quoting : false);
Again, the three MAG streams are specified with:
@papers = Papers(@uriPrefix); @authors = Authors(@uriPrefix); @paperAuthorAffiliation = PaperAuthorAffiliations(@uriPrefix);
Here, the script assumes the target list is first uploaded onto your Azure Data Lake and it contains the full names (that is, “DisplayName” in MAG) of the authors to be tracked, but if some authors have a common name that can be easily confused with others, the target list can optionally include the AuthorID and save the second statement to lookup IDs with names. The script also demonstrates how to compute a measure called saliency, with which Microsoft Academic ranks the search results by default. Saliency is a measure developed to avoid many known pitfalls of h-index. For example, if an author has published only ten papers, they can, by design, never have an h-index greater than 10 regardless how much impact and how many citations these ten papers have received, making the record look like it is work from a novice researcher. This problem is deftly avoided in saliency, and the results from the above script can be used to study this issue. A research paper describing saliency has been submitted for review. Please watch for it if you are interested in the details.
With these additional lookups and computation, the task still can be finished in 11 minutes and 14 seconds with a charge of U.S. $1.34:

Interestingly, this charge is not that different had we just computed the h-index for everyone in MAG. This can be done by removing the first three statements to look up a specific group of authors and count only their papers. Not surprisingly, the task is faster to complete (9 minutes 40 seconds) and the cost is less at U.S. $1.15:

In other words, the cloud is rather efficient in dealing with massive amounts of data and the costs of computing various indicators from MAG are often much lower than a cup of coffee.
Happy researching!