

Announcing: Hummingbird A library for accelerating inference with traditional machine learning models
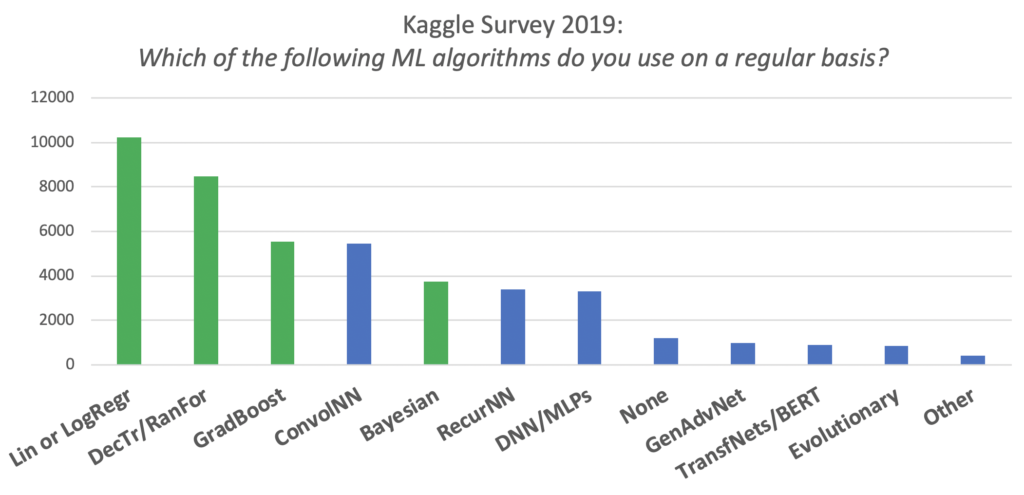
Traditional machine learning (ML), such as linear regressions and decision trees, is extremely popular. As shown in the chart below of the Kaggle Survey from 2019, the most popular ML algorithms are still traditional (shown in green).
Recently, the ever-increasing interest around deep learning and neural networks has led to a vast increase in processing frameworks that are highly specialized and optimized for running these types of computations. Frameworks like TensorFlow, PyTorch, and ONNX Runtime are built around the idea of a computational graph that models the dataflow of individual units and have tensors as their basic computational unit. These frameworks can run efficiently on hardware accelerators (e.g. GPUs) and their prediction performance can be further optimized with compiler frameworks such as TVM.
Unfortunately, traditional ML libraries and toolkits (such as Scikit-Learn, ML.NET, and H2O) are usually developed to run on CPU environments. While they may potentially exploit multi-core parallelism to improve performance, they do not use a common abstraction (such as tensors) to represent their computation. The lack of this common extraction means that for these frameworks to make use of hardware acceleration, one would need to have many implementations ((for each operator) x (for each hardware backend)) which does not scale well. This means that traditional ML is often missing out on the potential accelerations that deep learning and neural networks enjoy.
Announcing: Hummingbird
We are announcing Hummingbird, a library for accelerating inference (scoring/prediction) in traditional machine learning models. Internally, Hummingbird compiles traditional ML pipelines into tensor computations to take advantage of the optimizations that are being implemented for neural network systems. This allows users to seamlessly leverage hardware acceleration without having to re-engineer their models.
This first open-source release of Hummingbird currently supports converting the following trees to PyTorch:
- scikit-learn: DecisionTreeClassifier, RandomForestClassifier, RandomForestRegressor, GradientBoostingClassifier, and ExtraTreesClassifier
- XGBoost: XGBClassifier and XGBRegressor
- LightGBM: LGBMClassifier and LGBMRegressor
You can see a complete list of our support operators here. We are experimenting with many frameworks and backends, and we will continue to release additional operators and features in the upcoming weeks.
The code
Here’s an example of a RandomForestClassifier in scikit-learn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
# Create and train a RandomForestClassifier model
X, y = load_breast_cancer(return_X_y=True)
X = X.astype('|f4')
skl_model = RandomForestClassifier(n_estimators=500, max_depth=7)
skl_model.fit(X, y)
# Execute prediction using scikit-learn model
pred = skl_model.predict(X)
To enable Hummingbird and execute the scikit-learn model on PyTorch, users only need to add:
from hummingbird.ml import convert
And change the prediction code as follows:
# Use Hummingbird to convert the model to PyTorch model = convert(skl_model, 'pytorch') # Execute prediction on CPU using PyTorch pred_cpu_hb = model.predict(X)
The translated model can then be seamlessly executed on GPU as well:
model.to('cuda')
pred_gpu_hb = model.predict(X)
From here, you can experiment with different parameters, see speedups between CPU and GPU, and compare against your initial model. Also, check out some of our sample notebooks that provide additional examples and benchmarking functionality. You can see the documentation here.
The details
Hummingbird works by reconfiguring algorithmic operators such that we can perform more regular computations which are amenable to vectorized and GPU execution. Each operator is slightly different, and we incorporate multiple strategies. This example explains one of Hummingbird’s strategies for translating a decision tree into tensors involving GEMM (GEneric Matrix Multiplication), where we implement the traversal of the tree using matrix multiplications. (GEMM is one of the three tree conversion strategies we currently support.)
Below, we have a simple decision tree:
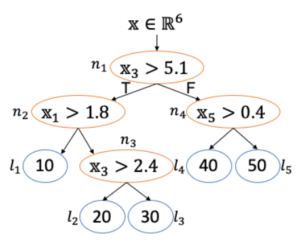
In this example, the tree takes as input a feature vector with six elements (x∈R6), four decision nodes (orange), and five leaf nodes (blue). We translate the decision tree into neural networks with two additional layers.
And now, the transformed tree:

- The first step takes all the features (x1 – x6) and evaluates all the conditions (nodes) of the tree together in one single one matrix multiplication.
- For the second step, we put all the leaf nodes (ℓ1-ℓ5) together and evaluate all of them together using matrix multiplication.
Although this leads to redundant computation from checking all conditions (not just the ones we know to be true), this is the key that allows us to do the vectorized computation. To offset this additional computation, we batch tensor operations and minimize the number of kernel invocations in addition to built-in tensor runtime optimizations.
Performance
We ran the example above of RandomForestClassifier on a NVidia P100 GPU-enabled VM. You can see the notebook here for the full example, which includes imports and test data setup.

For RandomForestClassifier with these parameters, Hummingbird provides a ~5x speedup on CPU, and ~50x speedup on GPU.
The table below shows some additional performance data for RandomForestClassifier, LGBMClassifier, and XGBClassifier. We tested Hummingbird on several of the datasets in NVidia’s GDM-bench with an average speed-up of 65x from scikit-learn to PyTorch. The chart reports the average of 5 runs for a batch size of 10K predictions, run on a NVidia P100 VM with 6 CPU cores.
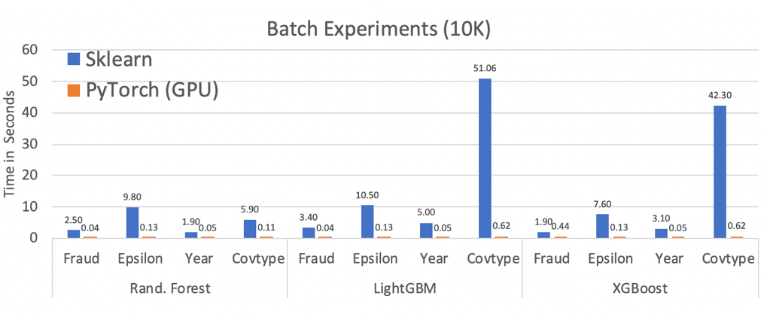
Our tech report provides additional details, where we have a full performance breakdown including per-operator results with varied batch sizes and on a variety of devices. Hummingbird is competitive and even outperforms (by up to 3x) hand-crafted kernels on micro-benchmarks, while enabling seamless end-to-end acceleration (with a speedup of up to 1200×) of ML pipelines.
Next steps
In the upcoming months, we look forward to adding many additional operators, input formats, and backend support, as we outline in our roadmap. We will soon release our linear and logistic regressors. We are investigating how to best integrate HB with existing platforms and are currently integrating Hummingbird with ONNX and its converters. We welcome contributions and collaborators.