

作者:谭旭
作为近期人工智能领域内的顶流之一,AIGC(AI-Generated Content 或 Generative AI)早已火爆出圈,频登各大互联网平台热搜。基于深度学习的内容生成在图像、视频、语音、音乐、文本等生成领域都取得了令人瞩目的成果。
由于现实世界中的信息在多数情况下呈现文本、图像和语音等多种模态,人类会通过综合运用多种感官来感知和理解现实世界,因此,如何赋予计算机这种综合理解多种模态的能力也成为了学术界的研究热点。
与文本生成更加关注抽象语义不同,声音和视觉模态还需要生成更多的细节信息。所以,声音和视觉内容(语音、音效、音乐、图像、视频等)的生成面临着一系列挑战:如何刻画声音视觉内容中复杂且高频的数据分布;如何建模生成过程中的一对多映射问题;如何利用大规模无标注数据解决数据稀疏性问题;在基于其它模态生成时,如何解决跨模态对齐问题等。
今天送上一个可以击破 AIGC 数据生成中这些难题的论文锦囊!希望大家可以在入坑 AIGC 领域之初能有所启发。
学习范式(Learning Paradigm)—— 高屋建瓴
一个好的学习范式能为研究者在探索复杂的深度学习问题时,指导设计方法和模型。在传统的数据理解任务中,深度学习先驱 Yoshua Bengio 等人倡导的表征学习 Representation Learning 非常值得参考。表征学习可以指导深度学习模型提高学习数据表征的能力,以增强对数据的理解。
[1] Bengio, Y., Courville, A., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798-1828.
https://arxiv.org/abs/1206.5538
而在 AIGC 的数据生成任务中,微软研究院的研究员们同 Yoshua Bengio 提出的 Regeneration Learning 的学习范式能为各个数据生成任务提供指导。它将复杂的带条件的数据生成任务 X—>Y 分解成两个阶段,X—>Y’ 和 Y’—>Y,其中X是条件信息,Y 是目标数据,而 Y’ 是 Y 的抽象表征,通过自监督的方法比如自编码器学到。
Regeneration Leaming 有几个好处:1) X—>Y’相比于 X—>Y 的一对多映射和虚假映射问题会大大减轻;2)Y’—>Y的映射可以通过自监督学习利用大规模的无标注数据进行预训练。
[2] Tan, X., Qin, T., Bian, J., Liu, T. Y., & Bengio, Y. (2023). Regeneration Learning: A Learning Paradigm for Data Generation. arXiv preprint arXiv:2301.08846.
https://arxiv.org/abs/2301.08846

编解码器 (Codec)——化繁为简
声音和视觉内容(语音、音效、音乐、图像、视频等)往往含有复杂的高频细节信息,因此科研人员们利用 Codec(编解码器)等方法,将承载高频细节的声音和视觉内容转化为抽象紧致的表征(离散 Token 或者连续向量),以降低后续数据生成的难度。相关论文,包括图像里的 Codec [3][4][5]以及声音里的 Codec [6]。
论文[3]是较早的一篇将连续图像音频数据通过 VQ-VAE(向量量化自编码器)转成离散 Token 的工作,而后续论文[4]将 VQ-VAE 和 GAN 结合进一步提升效果。
[3] Van Den Oord, A., & Vinyals, O. (2017). Neural discrete representation learning. Advances in Neural Information Processing Systems, 30.
https://arxiv.org/abs/1711.00937
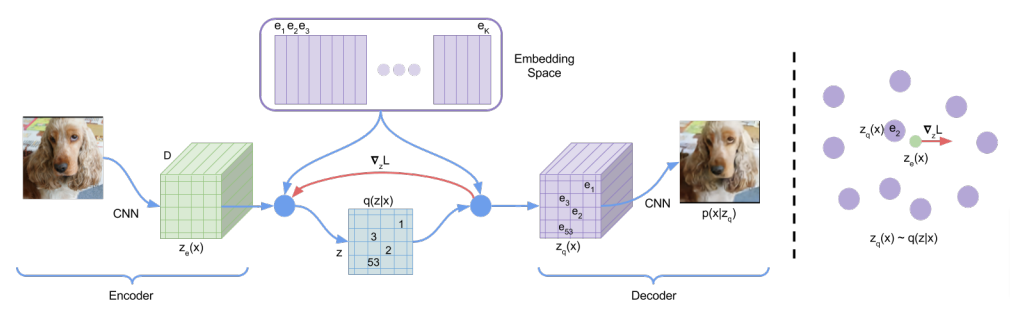
[4] Esser, P., Rombach, R., & Ommer, B. (2021). Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12873-12883).
https://arxiv.org/abs/2012.09841
论文[5]是文本到图像生成大火的 Stable Diffusion,和 VQ-VAE 和 VQ-GAN 不同的是,它更加偏向利用 VAE 将图像转为连续向量形式的抽象表征。
[5] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10684-10695).
https://arxiv.org/abs/2112.10752

论文[6]则利用 VQ-VAE 将语音波形转成离散 Token,为了增加重建质量,它采用了Residual Vector Quantizers(残差向量量化器)将一帧语音量化成多个残差 Token。
[6] Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., & Tagliasacchi, M. (2021). SoundStream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 495-507.
https://arxiv.org/abs/2107.03312

生成模型(Generative Model)——无中生有
强大的生成模型能细致而精准地刻画数据中的复杂分布,让模型能更好地从学习到的分布中采样,以实现数据的从无到有生成。
在当前流行的数据生成模型中,文本生成 GPT 系列比如 GPT 1/2/3 以及 ChatGPT 采用的是 Transformer 自回归模型,而在图像和音频生成中,有些采用的是扩散模型(比如 DALL-E 2,Imagen,Stable Diffusion,以及 DiffWave/ WaveGrad/ GradTTS),也有些采用的是自回归模型(比如 DALL-E,Parti,AudioLM)。关于各种生成模型的比较分析,大家可参考这篇文章https://zhuanlan.zhihu.com/p/591881660。
以下论文总结了典型的生成模型,包括变分自编码器 VAE [7],生成对抗网络 GAN [8],标准化流 Flow [9],扩散模型 Diffusion [10][11],以及自回归模型 AR [12]。

[7] Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
https://arxiv.org/abs/1312.6114
[8] Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial networks. Advances in Neural Information Processing Systems.
https://arxiv.org/abs/1406.2661
[9] Dinh, L., Krueger, D., & Bengio, Y. (2014). Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516.
https://arxiv.org/abs/1410.8516
[10] Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015, June). Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning (pp. 2256-2265). PMLR.
https://arxiv.org/abs/1503.03585
[11] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.
https://arxiv.org/abs/2006.11239
[12] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
https://arxiv.org/abs/2005.14165
跨模态对齐(Cross-Modal Alignment)——牵线搭桥
当利用条件信息作为输入来生成数据的时候,条件信息往往和生成数据的模态不一致。因此需要一个跨模态对齐模型来拉近两个模态之间的关系。
文本到图像生成模型 DALL-E 2 [13],通过文本-图像对齐模型 CLIP [14]来拉近图文之间的距离;文本到音乐音频生成模型 MusicLM [15],则通过文本-音乐音频对齐模型 MuLan [16]来拉近音乐和文字之间的距离。
通过利用对齐模型将输入模态转为共享的表征作为生成模型的条件输入,可大大降低生成模型处理不同模态输入的成本,使其专注于数据生成,提高生成效果。下列论文采集了 DALL-E 2 都在用的文本-图像对齐模型 CLIP [14]以及 MusicLM 在用的文本-音频对齐模型 MuLan [16],这些方法值得一试!
[13] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125.
https://arxiv.org/abs/2204.06125
[14] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR.
https://arxiv.org/abs/2103.00020
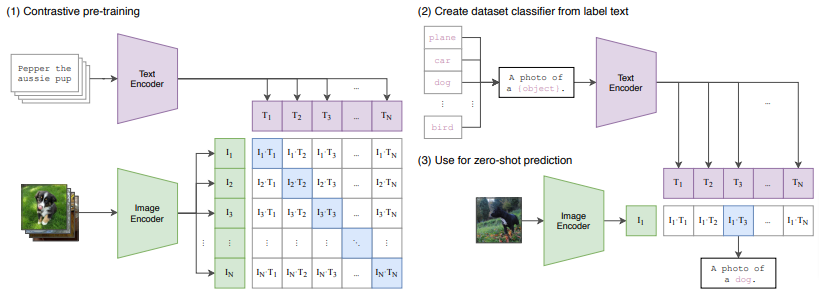
[15] Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., … & Frank, C. (2023). Musiclm: Generating music from text. arXiv preprint arXiv:2301.11325.
https://arxiv.org/abs/2301.11325
[16] Huang, Q., Jansen, A., Lee, J., Ganti, R., Li, J. Y., & Ellis, D. P. (2022). MuLan: A joint embedding of music audio and natural language. arXiv preprint arXiv:2208.12415.
https://arxiv.org/abs/2208.12415
