

Imagine a purely hypothetical scenario where the Bing team wants to implement an icon that allows customers to view content in Microsoft News. Imagine that the Bing team, not knowing how this would affect user experience, wants to A/B test this feature in order to ensure that no harm to user experience is done. In this example, it would be important to look both at Bing data AND Microsoft News data with this A/B test because it is possible that the user’s experience on either product could be affected by such a change. Multiple parts of both stacks would need to be evaluated, as we want to not only test changes to user satisfaction, but also product performance. In addition, we want to track user cannibalization in case this feature affects Microsoft News usage for users even after clicking on the icon, as well as users who never clicked it at all. This presents a difficulty, since Bing and Microsoft News have completely different telemetry systems and backends.
This is a problem that we have faced often at Microsoft, and we have found multiple different ways to tackle this problem. Here I’ve given an example with two large products in Bing and Microsoft News where each could be its own company, but “product” could also be as small as different versions of the same software (e.g., an iOS version and Mac version). In this blog post we’ll talk about the high-level requirements needed, investigate an online and offline option, talk about privacy concerns, and discuss other considerations.
What is A/B Testing?
A/B testing is an industry standard method for determining the user impact of a potential change in a technology stack [1]. It involves randomizing user traffic to a product between two experiences, computing the difference in metrics, and running statistical tests to rule out any differences due to noise. Randomization is done against an identifier (called the “randomization unit”) and the experiences are called treatments (so the experience a user is in is often called “treatment assignment”). We perform statistical tests to determine the treatment effect on the product. Analysis can then be split by different identifying information (segments) or can be examined by zooming in to data that meets a certain condition relevant to the experience being tested (this is called “triggering“). A common problem at Microsoft is how to perform an A/B test on one product but measure the impact of that test on another product.
How to run A/B Tests Across Products?
A/B testing across products involves seeing the impact on one product from an A/B test conducted on another product (or multiple other products). These products could have different treatment assignment processes, different user bases, and different logs in different physical locations, and thus the problem can be rather complex. With that said, regardless of the individual complexities of your cross-product scenario, there are certain things that need to be present for cross-product A/B testing to work.
When laying out this scenario, let us assume that you are running an A/B test on Product X and want to see the impact on Product Y. In order to create a scorecard to see the impact, we need the following in the same place:
- Product Y’s diagnostic data for users who both did and didn’t interact with Product X
- Product X’s randomization unit, which can be tied to Product Y’s diagnostic data (see the last section if this is not possible)
- Product X’s treatment assignment, which can be tied to Product Y’s diagnostic data
- Any relevant trigger and segment information (might be from Product X’s logs or Product Y’s logs) that can be tied to Product Y’s diagnostic data
This then allows us to create a data view where we have all of Product Y’s data tied to Product X’s randomization unit, treatment assignment, and trigger/segment information. This data view can then be used to calculate metrics for Product Y based on Product X’s A/B test, thus allowing us to make a more informed decision about the overall impact of the proposed changes to Product X.
It’s important to note that there are situations where the A/B test changes the number of users who use Product Y, leading to a Sample Ratio Mismatch [2]. In this case it is important to use all of the treatment assignment for Product X even if there is no corresponding data for Product Y. In doing this you can impute zeroes or null values for those users who didn’t actually use Product Y. This will limit the types of metrics you can reliably compute, but might be a necessary step.
There are three main ways to enable this data view for cross-product A/B testing: online, offline and hybrid. We discuss each of them next. Each method has pros and cons, and could be taken depending on engineering concerns, privacy considerations, organizational considerations for data handling, as well as user trust considerations.
Online Method
With the Online Method we want to natively log information from one product into the other. There are two options here:
- Log Product Y’s diagnostic data within Product X
- Get Product X’s treatment assignment and randomization unit logged with Product Y.
The first option is ideal if there are only a few pieces of data that are needed from Product Y (e.g., click, revenue, and time on product). The second option is ideal if there is a large amount of data that is needed from Product Y (such as if you want to get a full diagnostic report from Product Y). Here is a diagram highlighting both options.
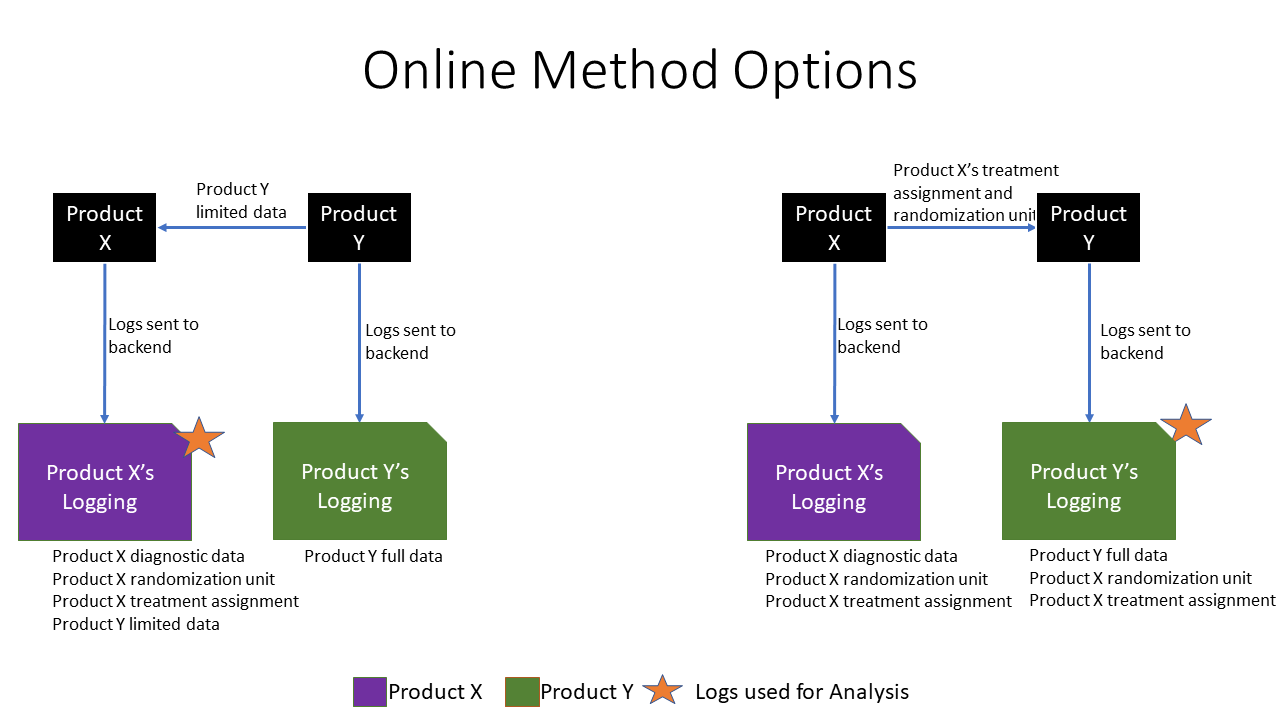
Now that we know what to pass, we need to have an online method to pass that data. If it is a web service then in the header request to that service you can pass along the required information. For a client application the necessary data can be stored natively in the logs of that client.
It’s important that in the Online Method every single request between the products passes the necessary information. This allows us to attribute Product Y’s data to Product X’s treatment assignment and randomization unit with the highest fidelity. If this isn’t done, we might have a situation where we can only partially see the impact of the A/B test from Product X on Product Y.
The main disadvantage of the Online Method is the significant engineering cost which needs to happen upfront. In order to pass information in real time between products, multiple changes to product interfaces need to be planned and performed. There are also other costs and concerns with this method. For instance, due to the increased payload size, there might be performance concerns. There are also privacy concerns that we will address in a section below. All of these concerns need to be addressed before starting the first cross-product A/B test.
Offline Method
The Online Method discussed above focuses on real-time exchange of data between the products. Another way to solve our problem of cross-product A/B testing is to bring the data together in batch. We call this the “Offline Method”. In this method we have Product X’s data, and Product Y’s data, and we need to join the data together to perform analysis. This can be tricky, since the join rate might not be 100%. The analysis needs to then account for this. We also here need to consider a difference in the timing of logs: web services often dump data instantaneously while client applications often cache data to send it periodically to the server. The join rate between web service and client application logs would then increase the longer you wait, as you give more instances of the client application a chance to send their data as time goes on. Also, if the products have different ways of logging time (such as using computer time vs server time) then joining on time might not be reliable and a different join key should be considered (such as an identifier for the payload that sends information to both products).
The main disadvantage of this approach is that its feasibility greatly depends on the product and legal scenario. There are several instances where moving or joining data is simply not allowed or desired, making this option a non-starter.
Hybrid Approaches
We mentioned meeting the requirements through the Online Method or the Offline Method, but it is possible to perform cross-product A/B testing using both methods. For example, it might be the case that you send the randomization unit and a one way hash of the treatment assignment to the target product (this is done online) and then you do a join from that treatment assignment hash to a table with the true treatment assignment (offline). This could be done since the treatment assignment might be too large to send online. A diagram below highlights this example. Hybrid approaches are often used within Microsoft for cross-product A/B testing.

Regardless of the method(s) chosen, you should always be cognizant of any data loss, join rates, and caveats with your analysis. Most importantly, you must focus on privacy, trust, and mindful data handling, which we explore more in the next section.
Trust and Privacy Concerns
When enabling cross-product A/B testing, it is important to keep all customer obligations around data and security while adhering to Microsoft’s standards of privacy (opens in new tab). Data must always be kept within the allowed geographical boundaries and used only for the intended and approved purpose. Microsoft runs on trust, and as a result we need to be very careful in ensuring that any attempts at cross-product analysis not only doesn’t break any legal obligations, but also doesn’t harm the trust that our customers put in us. We also instill strict data retention policies and data delete processes, which are especially important during cross-product A/B testing. For this reason it is important to consult with security, legal, and privacy experts before implementing a solution for A/B testing across products.
What if the Analysis Unit is Different from the Randomization unit
The discussion above applies to a best case scenario where you are able to get the same randomization unit attached to each product’s logs for analysis purposes. For various reasons, it may not always be possible to share the preferred randomization unit between products. In those cases, the best option will be to perform analysis on an identifier that is different than the randomization unit. This has been discussed extensively in [3], and here we just discuss some highlights briefly. For a thorough investigation into analyzing at a point other than the randomization unit, it is highly recommended reading through that paper.
If we assume that the randomization unit is an independent unit as per the stable unit treatment value assumption (SUTVA) [4], then we really need to consider the following options:
- We want to analyze at a unit that is 1:1 with the randomization unit, or above the randomization unit. Here it is safe to simply use that unit and perform standard variance calculations.
- We want to analyze at a unit below the randomization unit. This requires the use of the delta method for correct variance calculation. If the delta method is not available, then we recommend against this (this can be avoided by instead starting the experiment on the product with the lower unit)
For more information on choosing the correct randomization unit, refer to our previous blog post [5].
– Kaska Adoteye, Microsoft Experimentation Platform
References
[1] Kohavi, R., Tang, D., & Xu, Y. (2020). Trustworthy Online Controlled Experiments: A practical Guide to A/B Testing. Cambridge: Cambridge University Press. doi:10.1017/9781108653985
[2] Fabijan, A., Blanarik, T., Caughron, M., Chen, K., Zhang, R., Gustafson, A., Budumuri, V.K., & Hunt, S. (2020, Sep 14). Diagnosing Sample Ratio Mismatch in A/B Testing. Retrieved from Experimentation Platform Blog: https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-pre-experiment-stage/
[3] Deng, A., Lu, J., & Litz, J. (2017, February). Trustworthy Analysis of Online A/B Tests: Pitfalls, challenges and solutions. WSDM ’17: Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, 641-649. doi:10.1145/3018661.3018677
[4] Imbens, G. W., & Rubin, D. B. (2015). Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press.
[5] Machmouchi, W., Gupta, S., Zhang, R., & Fabijan, A. (2020, July 31). Patterns of Trustworthy Experimentation: Pre-Experiment Stage. Retrieved from Experimentation Platform Blog: https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-pre-experiment-stage/