

Paper (opens in new tab) / Code (opens in new tab) / Demo (opens in new tab) / Docs (opens in new tab)
Modern machine learning models are known to fail in ways that aren’t anticipated during training these models. These include all sorts of distribution shifts that the model might experience during deployment in complex real-life settings. In the context of computer vision for example, it has been shown by several works that models suffer in the face of small rotations (opens in new tab), common corruptions (opens in new tab) (such as snow or fog), and changes to the data collection pipeline (opens in new tab). While such brittleness is widespread, it is often hard to understand its root causes, or even to characterize the precise situations in which this unintended behavior arises.

How do we then comprehensively diagnose model failure modes? One way to do this is to deploy our models in the real-world and eventually collect some real-world failure cases. But clearly the stakes are often too high to simply do this. There has been a line of work in computer vision research that is focused on identifying systematic sources of model failure: which include examining the effects of unfamiliar object orientations (opens in new tab), misleading backgrounds (opens in new tab), or conflicts between texture and shape (opens in new tab). Such analyses have revealed patterns of performance degradation in vision models – still, each such analysis requires its own set of (often complex) tools, time, and effort. Our question is thus: can we support reliable discovery of model failures in a systematic, automated, and unified way?
To address this, in collaboration with researchers at MIT, we introduce 3Debugger (3DB): a framework for automatically identifying and analyzing the failure modes of computer vision models. This framework makes use of a 3D simulator to render images of near-realistic scenes that can be fed into any computer vision system. Users can specify a set of extendable and composable transformations within the scene, such as pose changes, background changes, or camera effects, which we refer to as “controls”. We show examples of such controls in Fig. 1.

Fig. 1: Examples of “controls” in 3DB, using Blender as the 3D simulator.
Once the user has specified a set of controls of interest, the system performs a guided search, evaluation, and aggregation derived from these transformations. 3DB achieves this by instantiating and rendering a myriad of object configurations according to the transformations, records the behavior of the model on each rendered scene, and finally presents the user with an interactive, user-friendly summary of the model’s performance and vulnerabilities. 3DB is general enough to enable users to, with little-to-no effort, re-discover insights from prior work on robustness to pose, background, and texture, among others. Users can even compose these transformations to understand their interplay, while still being able to disentangle their individual effects, or easily write their own if required. An overview of the workflow of 3DB is shown in Fig. 2.
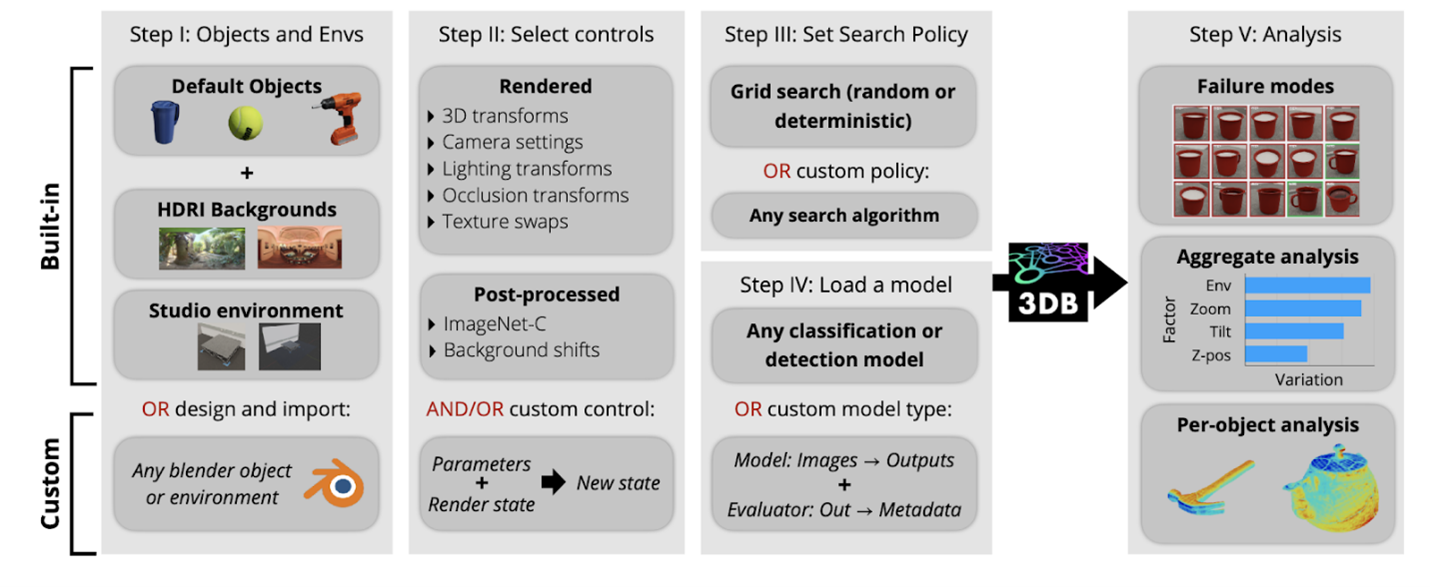
Fig.2: The workflow of 3DB.
As an example, let us try to evaluate how robust the standard ImageNet-pretrained ResNet-18 model is at classifying a coffee mug. The highly configurable nature of 3DB allows one to set up the model of interest, the renderer, as well as the transformations of interest through a YAML configuration file. 3DB reads this configuration file and initializes the renderer and the model accordingly. Once initialized, 3DB renders several synthetic images according to the desired controls, performs inference on these images and displays the results in a web dashboard, mapping the changing parameters to success/failure.

Some interesting findings from 3DB for this coffee mug example are:
- Complex backgrounds result in bad classification performance.
- ImageNet pretrained models are sensitive to texture.
- Classification accuracy changes based on which liquid is inside the mug.
3DB is also capable of finding failure modes (e.g. due to extreme viewpoints and poses) in simulation that transfer to the real world. Fig. 3 shows the agreement, in terms of model correctness, between the model predictions within 3DB and its predictions in the real-world. For each object, we selected five configurations that 3DB found to be correctly classified in simulation, and five misclassified; we recreated and deployed the model on each scene in the physical world. The positive (resp., negative) predictive value is the rate at which correctly (resp. incorrectly) classified examples in simulation were also correctly (resp., incorrectly) classified in the physical world.

Overall, 3DB is a scalable, extendable, and unified framework for diagnosing failure modes in vision models using high-fidelity rendering. We refer the reader for our paper to learn more about the use cases of 3DB, where we demonstrated the efficacy of 3DB by applying it to a variety of use cases including disentangling the effects of different types of brittleness, discovering model biases, analyzing specific model decisions in depth, and identifying vulnerabilities and worst-case environmental configurations. We are releasing 3DB as a library alongside a set of example analyses (opens in new tab), guides (opens in new tab) and documentation (opens in new tab). 3DB is designed with extensibility as a priority; we encourage the community to build upon the framework by adding more controls and policies that provide new insights into the vulnerabilities of vision models.
This work was a collaborative effort between Microsoft Research and MIT. Researchers involved in this work were Guillaume Leclerc, Hadi Salman, Andrew Ilyas, Sai Vemprala, Logan Engstrom, Vibhav Vineet, Kai Xiao, Pengchuan Zhang, Shibani Santurkar, Greg Yang, Ashish Kapoor, Aleksander Mądry.