

Realizing AI strategy with a problem-first approach
Jomit Vaghela | Cloud Solution Architect, US EC Industry, Microsoft
In collaboration with the National Association of Manufacturers
In my earlier post, I discussed basics of machine learning (ML) and techniques that can drive powerful outcomes for manufacturers. Now, let’s discuss the approach for realizing those outcomes.
I start every ML discussion with two questions: What is the business problem? And, what is the hypothesis? Starting this way forces everyone to think about what problem we are trying to solve, what data we might need, what our acceptance criteria should be, and what actions we should take based on the predictions. The ability to answer these questions varies depending on the organization’s AI Maturity level, but going through the questions provides key insights into the actual problem. And while these problems might vary in terms of complexity, the basic approach to tackling them remains the same.
What is a problem-first approach?
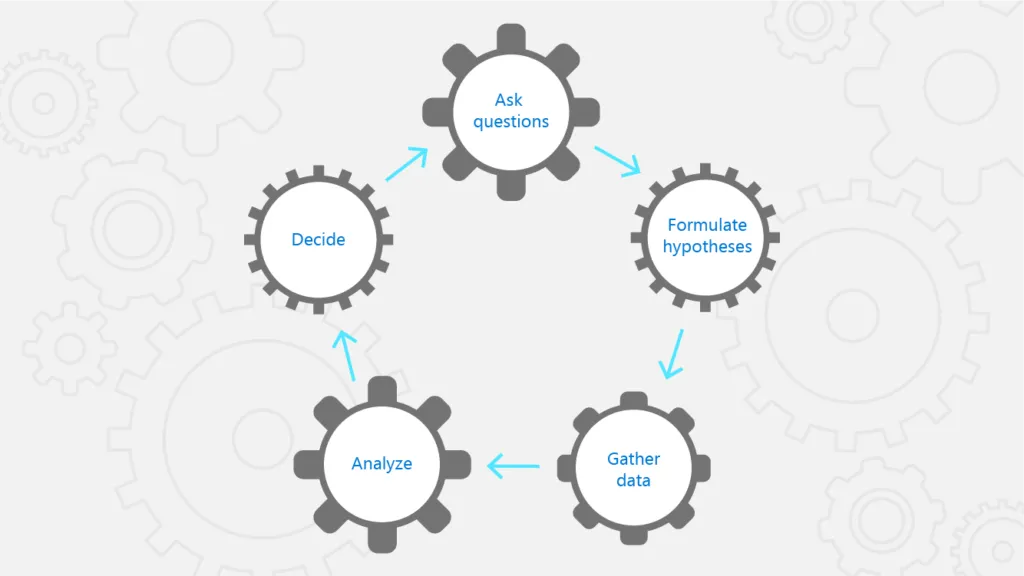
Broadly, it’s about identifying the problem first and then understanding how to organize money, technology, and talent to best execute against solving the problem. The first step in this approach is to frame the problem correctly, and the key to that is asking the right questions. A typical machine learning analytics process looks like this:
- Ask questions
- Formulate a hypothesis and predictions
- Gather data to test the predictions
- Analyze the data
- Decide: accept, reject, or refine the hypothesis?
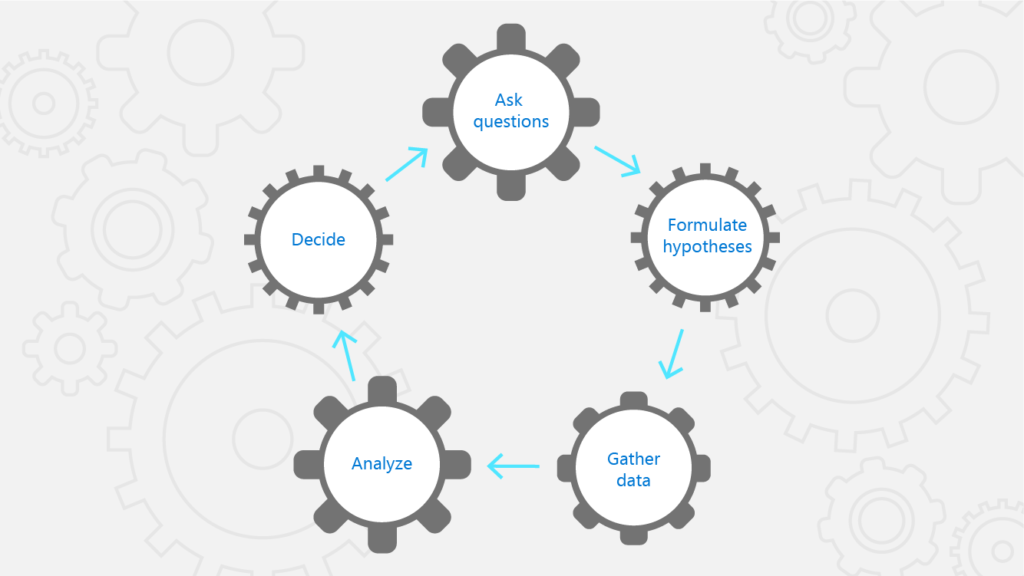
If we start with the right question, addressing a specific business problem, we are more likely to get an acceptable process in the end. It is also critical to work side-by-side with the business to formulate a clear hypothesis and define the acceptance criteria for the machine learning process. For example, for business problems like increasing machine up-time and asset ROI, a typical question could be, “What is the probability that a machine goes down within the next seven days due to failure of a component?” Based on this question, one hypothesis could be to frame this as a predictive maintenance problem and look at data elements like features of the machine, operating-condition data collected from sensors on that machine, repair history of the machine, and failure history of the machine. From there, we can build a prediction model.
Since machine learning prediction results are probabilistic, it’s important for businesses to define clear thresholds of acceptable probability for results that should lead to action. Each step in the machine learning analytics process requires a unique set of skills that are typically outside of a traditional IT + OT skillset.
What roles do I need?
There are three main areas of work required for the machine learning analytics process:
- Data analysis
- Data modeling
- Data engineering
Data analysis translates a business problem or need into the right question. It requires domain knowledge. It also includes gathering the initial data and applying statistical tools for summarizing, aggregating, and visualizing the raw data.
Data modeling uses machine learning techniques like supervised learning and unsupervised learning along with custom algorithm development aspects like dimensionality reduction, feature engineering, and hyper-parameter tuning to create a model for the hypothesis.
Data engineering involves creating end-to-end pipelines to enable data analysis and data modeling at scale. It also includes applying software engineering to ensure security, maintainability, and high availability of these pipelines.
Typically, each of these work areas is mapped to a role, and these roles are part of a data science or data analytics team that works closely with IT, OT, and business to enable the full machine learning analytics process. Join us for a live webinar to see how this approach can help you build your own end-to-end AI solutions at scale.
Ready to learn more about intelligent manufacturing?
Get The Manufacturer’s Guide to Digital Transformation: aka.ms/DTGuideManufacturing


